PDP 2
기능 상호 작용
특징이 예측 모델에서 서로 상호 작용할 때 한 특징의 효과가 다른 특징의 값에 따라 달라지기 때문에 예측을 특징 효과의 합으로 표현할 수 없습니다.
아리스토텔레스의 술어 "전체는 부분의 합보다 크다"는 상호 작용이있을 때 적용됩니다.
기능 상호 작용?
기계 학습 모델이 두 가지 특성을 기반으로 예측을 수행하는 경우 예측을 상수 항, 첫 번째 특성에 대한 용어, 두 번째 특성에 대한 용어 및 두 특성 간의 상호 작용에 대한 용어의 네 가지 용어로 분해 할 수 있습니다.
두 기능 간의 상호 작용은 개별 기능 효과를 고려한 후 기능을 변경하여 발생하는 예측의 변화입니다.
예를 들어, 모델은 집 크기 (크거나 작음) 및 위치 (좋거나 나쁨)를 특징으로 사용하여 집의 가치를 예측하여 네 가지 가능한 예측을 생성합니다.
위치/ 크기/ 예측
좋은/ 큰/ 300,000
좋은/ 작은/ 200,000
나쁜/ 큰/ 250,000
나쁜/ 작은/ 150,000
상수 항 (150,000), 크기 특성에 대한 효과 (큰 경우 +100,000, 작은 경우 +0) 및 위치에 대한 효과 (좋으면 +50,000, 나쁜 경우 +0) ). 이 분해는 모델 예측을 완전히 설명합니다.
모델 예측을 다음 부분으로 분해합니다.
모델 예측은 크기 및 위치에 대한 단일 기능 효과의 합계이기 때문에 상호 작용 효과가 없습니다.
작은 집을 크게 만들면 위치에 관계없이 예측이 항상 100,000 씩 증가합니다.
또한 크기에 관계없이 좋은 위치와 나쁜 위치 간의 예측 차이는 50,000입니다.
이제 상호 작용이있는 예를 살펴 보겠습니다.
위치/ 크기/ 예측
좋은/ 큰/ 400,000
좋은/ 작은/ 200,000
나쁜/ 큰/ 250,000
나쁜/ 작은/ 150,000
상호 작용 강도를 추정하는 한 가지 방법은 예측의 변동이 특징의 상호 작용에 의존하는 정도를 측정하는 것입니다.
이 측정을 H- 통계라고하며 Friedman과 Popescu (2008) 32에 의해 도입되었습니다.
예측 테이블을 다음 부분으로 분해합니다.
상수 항 (150,000), 크기 특성에 대한 효과 (큰 경우 +100,000, 작은 경우 +0) 및 위치에 대한 효과 (좋으면 +50,000, 나쁘면 +0) ). 이 테이블의 경우 상호 작용에 대한 추가 용어가 필요합니다.
집이 크고 좋은 위치에있는 경우 +100,000입니다.
이 경우 큰 집과 작은 집 간의 예측 차이는 위치에 따라 다르기 때문에 크기와 위치 간의 상호 작용입니다.
이론 : Friedman의 H- 통계
우리는 두 가지 경우를 다룰 것입니다.
첫째, 모델의 두 기능이 서로 상호 작용하는지 여부와 그 정도를 알려주는 양방향 상호 작용 측정입니다.
둘째, 기능이 모델에서 다른 모든 기능과 상호 작용하는지 여부와 그 정도를 알려주는 총 상호 작용 측정 값입니다.
이론적으로는 여러 기능 간의 임의 상호 작용을 측정 할 수 있지만이 두 가지가 가장 흥미로운 경우입니다.
두 기능이 상호 작용하지 않으면 다음과 같이 부분 종속성 함수 를 분해 할 수 있습니다 (부분 종속성 함수가 0의 중심에 있다고 가정).
PDjk(xj,xk)=PDj(xj)+PDk(xk)
어디 PDjk(xj,xk) 두 기능의 양방향 부분 의존 함수이며 PDj(xj) 과 PDk(xk) 단일 기능의 부분 의존 기능.
마찬가지로 기능이 다른 기능과 상호 작용하지 않는 경우 예측 기능을 표현할 수 있습니다.
f^(x) 부분 의존 함수의 합계로, 첫 번째 합계는 j에만 의존하고 두 번째 합계는 j를 제외한 다른 모든 기능에 의존합니다.
f^(x)=PDj(xj)+PD−j(x−j)
어디 PD−j(x−j) j 번째 특성을 제외한 모든 특성에 의존하는 부분 의존 함수입니다.
이 분해는 상호 작용없이 부분 의존 (또는 전체 예측) 함수를 표현합니다 (특징 j와 k 사이 또는 각각 j와 다른 모든 특성 사이).
다음 단계에서는 관찰 된 부분 의존 함수와 상호 작용이없는 분해 함수의 차이를 측정합니다.
부분 의존성 (두 기능 간의 상호 작용 측정) 또는 전체 기능 (특성 및 다른 모든 기능 간의 상호 작용 측정)의 출력 분산을 계산합니다.
상호 작용에 의해 설명되는 분산의 양 (관찰 된 PD와 상호 작용이없는 PD의 차이)이 상호 작용 강도 통계로 사용됩니다.
통계는 상호 작용이 전혀 없으면 0이고 모든 분산이 있으면 1입니다.
PDjk 또는 f^부분 의존 함수의 합으로 설명됩니다.
두 기능 간의 상호 작용 통계가 1이면 각 단일 PD 함수가 일정하고 예측에 대한 효과가 상호 작용을 통해서만 발생 함을 의미합니다.
H- 통계량도 1보다 클 수 있으므로 해석하기가 더 어렵습니다.
이는 2 원 교호 작용의 분산이 2 차원 부분 의존도의 분산보다 클 때 발생할 수 있습니다.
수학적으로, 특징 j와 k 사이의 상호 작용에 대해 Friedman과 Popescu가 제안한 H- 통계량은 다음과 같습니다.
Hjk2=∑i=1n[PDjk(xj(i),xk(i))−PDj(xj(i))−PDk(xk(i))]2/∑i=1nPDjk2(xj(i),xk(i))
기능 j가 다른 기능과 상호 작용하는지 여부를 측정 할 때도 마찬가지입니다.
Hj2=∑i=1n[f^(x(i))−PDj(xj(i))−PD−j(x−j(i))]2/∑i=1nf^2(x(i))
H- 통계는 모든 데이터 포인트에 대해 반복하고 각 포인트에서 부분 의존성을 평가해야하므로 모든 n 데이터 포인트로 수행되므로 평가하는 데 비용이 많이 듭니다.
최악의 경우, 양방향 H- 통계량 (j 대 k)을 계산하기 위해 기계 학습 모델 예측 함수에 대한 2n 2 호출이 필요 하고 전체 H- 통계량 (j 대 전체)에 대해 3n 2 호출이 필요합니다 .
계산 속도를 높이기 위해 n 개의 데이터 포인트에서 샘플링 할 수 있습니다.
이것은 부분 의존성 추정치의 분산을 증가시키는 단점이있어 H- 통계를 불안정하게 만듭니다.
따라서 계산 부담을 줄이기 위해 샘플링을 사용하는 경우 충분한 데이터 포인트를 샘플링해야합니다.
Friedman과 Popescu는 또한 H- 통계량이 0과 유의하게 다른지 여부를 평가하기 위해 검정 통계량을 제안합니다.
귀무 가설은 상호 작용이 없다는 것입니다.
귀무 가설 하에서 상호 작용 통계를 생성하려면 특성 j와 k 또는 다른 모든 항목간에 상호 작용이 없도록 모델을 조정할 수 있어야합니다.
이것은 모든 유형의 모델에서 가능하지 않습니다.
따라서이 테스트는 모델과 무관하지 않고 모델에 따라 다르므로 여기서 다루지 않습니다.
상호 작용 강도 통계는 예측이 확률 인 경우 분류 설정에도 적용될 수 있습니다.
예
실제로 기능 상호 작용이 어떤 모습인지 살펴 보겠습니다!
날씨 및 캘린더 기능을 기반으로 대여 자전거 수를 예측하는 서포트 벡터 머신에서 기능의 상호 작용 강도를 측정합니다 .
다음 그림은 기능 상호 작용 H- 통계량을 보여줍니다.
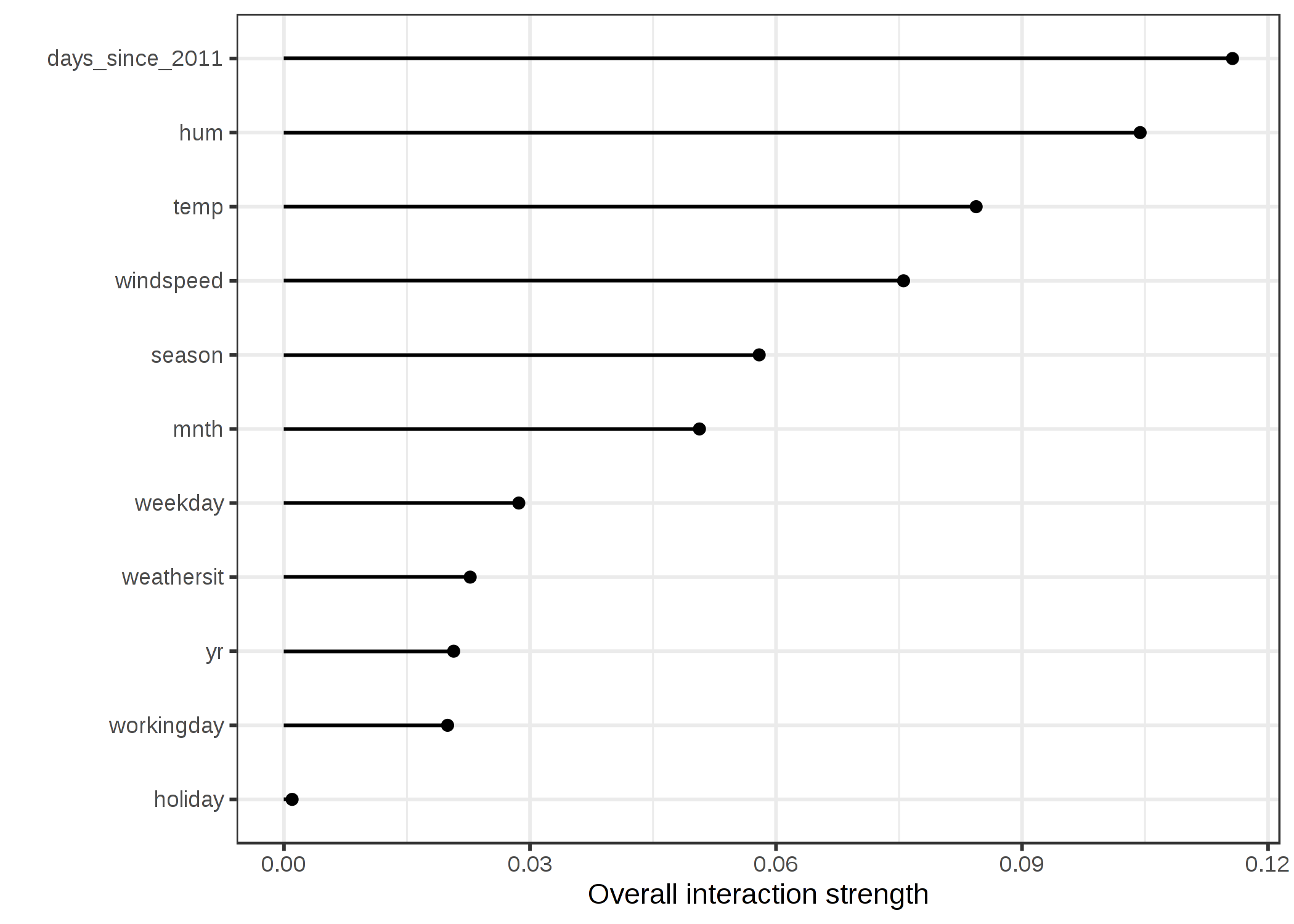
그림 5.24 : 자전거 대여를 예측하는 지원 벡터 머신에 대한 다른 모든 기능과 각 기능의 상호 작용 강도 (H- 통계). 전반적으로 기능 간의 상호 작용 효과는 매우 약합니다 (특성별로 설명 된 분산의 10 % 미만).
다음 예에서는 분류 문제에 대한 상호 작용 통계를 계산합니다.
몇 가지 위험 요인을 고려 하여 자궁 경부암 을 예측하도록 훈련 된 무작위 숲의 기능 간의 상호 작용을 분석합니다 .
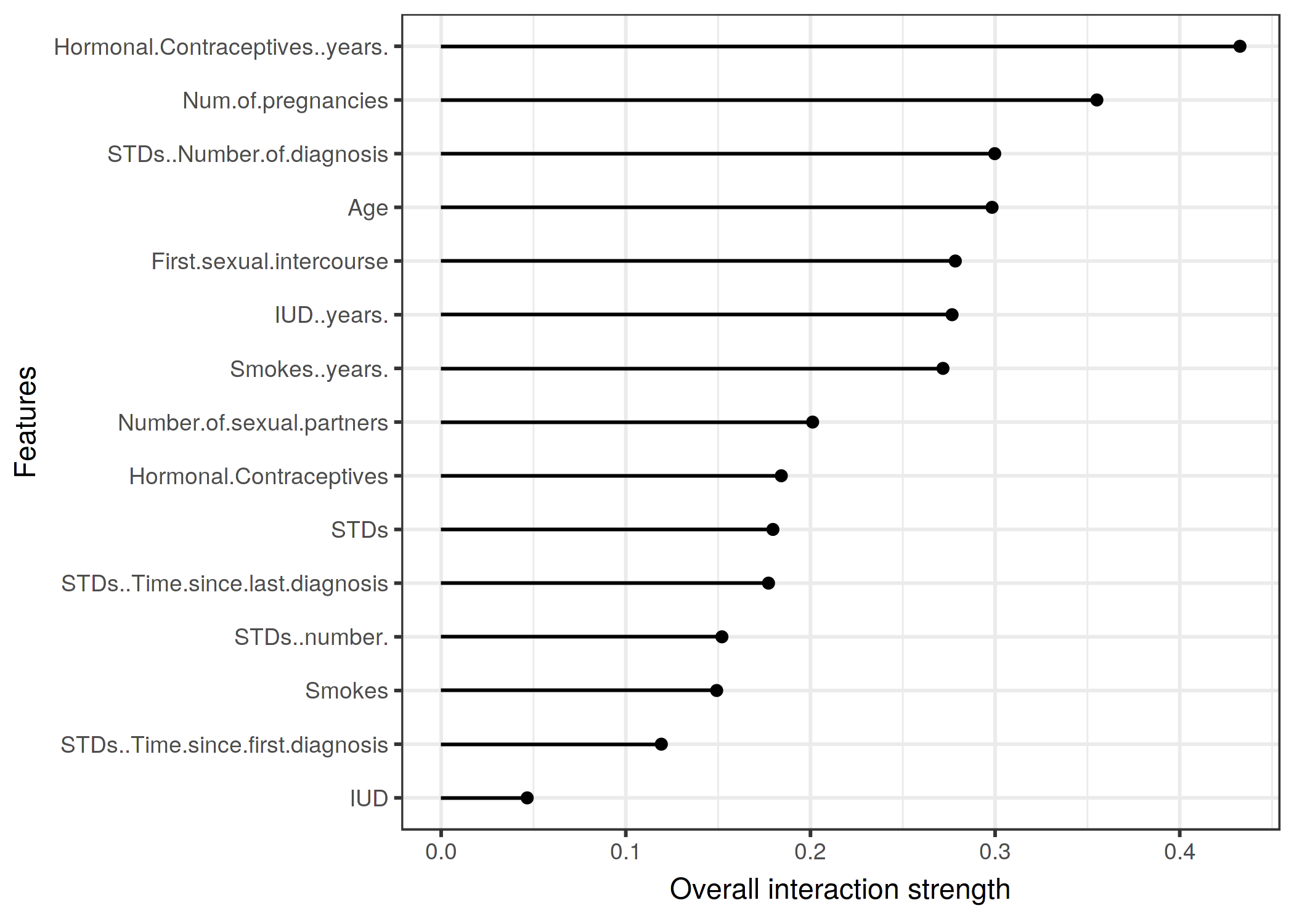
그림 5.25 : 자궁 경부암 확률을 예측하는 임의의 숲에 대한 다른 모든 기능과 각 기능의 상호 작용 강도 (H- 통계). 호르몬 피임약 사용 기간은 다른 모든 기능과의 상대적 상호 작용 효과가 가장 높으며 그 다음으로 임신 횟수가 이어집니다.
각 기능과 다른 모든 기능의 기능 상호 작용을 살펴본 후 기능 중 하나를 선택하고 선택한 기능과 다른 기능 간의 모든 양방향 상호 작용에 대해 자세히 알아볼 수 있습니다.
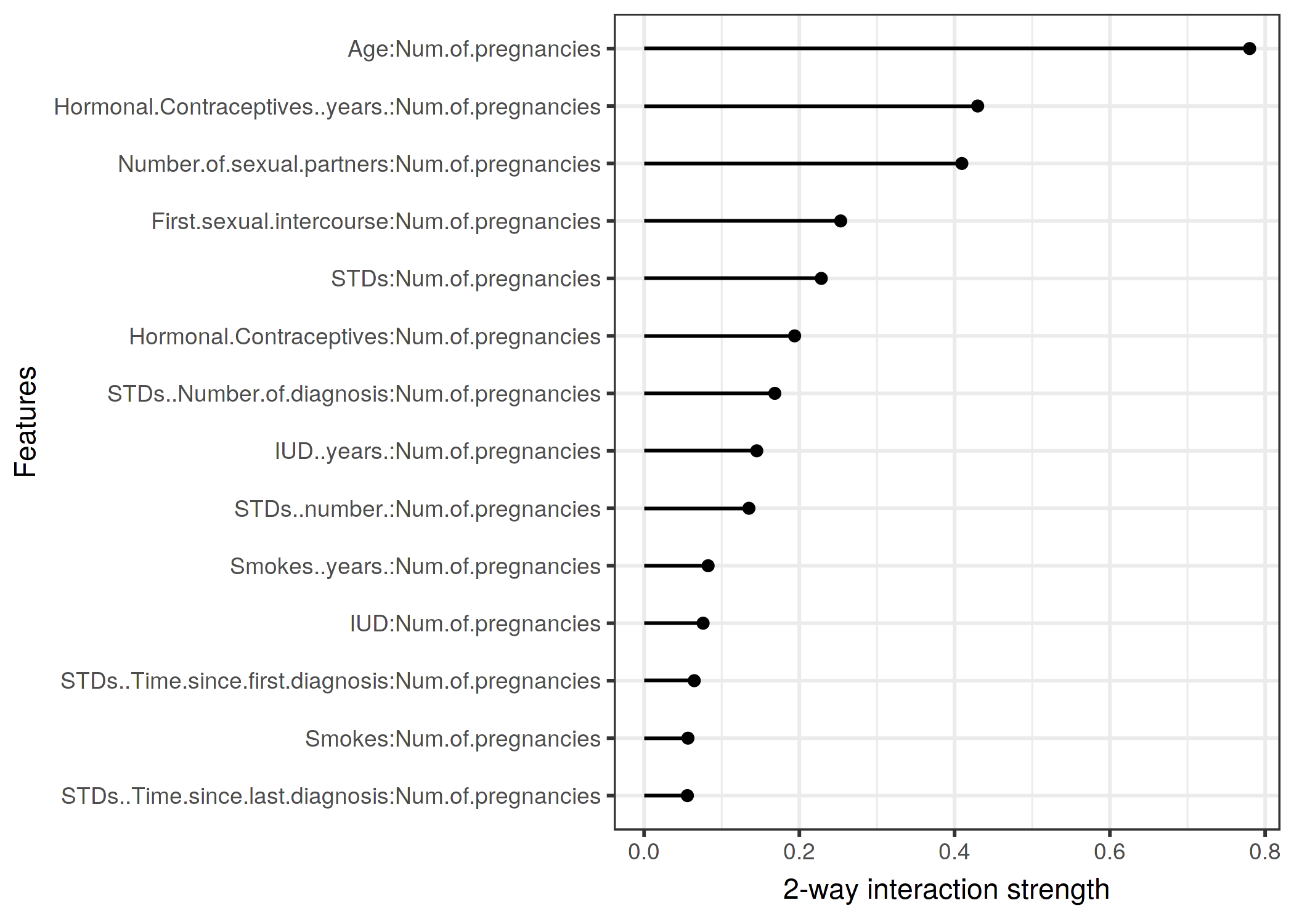
그림 5.26 : 임신 횟수와 서로의 특징 사이의 양방향 상호 작용 강도 (H- 통계). 임신 횟수와 나이 사이에는 강한 상호 작용이 있습니다.
장점
상호 작용 H- 통계는 부분 의존 분해를 통한 기본 이론 을 가지고 있습니다.
H- 통계에는 의미있는 해석이 있습니다 . 상호 작용은 상호 작용에 의해 설명되는 분산의 공유로 정의됩니다.
통계는 차원 이 없으므로 기능과 모델간에 비교할 수 있습니다.
통계 는 특정 형태에 관계없이 모든 종류의 상호 작용을 감지합니다 .
H- 통계를 사용하면 3 개 이상의 기능 간의 상호 작용 강도와 같은 임의의 더 높은 상호 작용 을 분석 할 수도 있습니다.
단점
가장 먼저 눈에 띄는 점 : 상호 작용 H- 통계는 계산 비용이 많이 들기 때문에 계산하는 데 오랜 시간이 걸립니다 .
계산에는 주변 분포 추정이 포함됩니다.
이러한 추정치는 모든 데이터 포인트를 사용하지 않는 경우 에도 특정 분산 이 있습니다.
즉, 포인트를 샘플링 할 때 추정치도 실행마다 다르며 결과가 불안정 할 수 있습니다 .
안정적인 결과를 얻을 수있는 충분한 데이터가 있는지 확인하기 위해 H- 통계 계산을 몇 번 반복하는 것이 좋습니다.
상호 작용이 0보다 유의하게 큰지 여부는 불분명합니다.
통계 테스트를 수행해야하지만이 테스트는 아직 모델과 무관 한 버전에서 사용할 수 없습니다 .
테스트 문제와 관련하여 H- 통계량이 상호 작용이 "강하다"고 간주하기에 충분히 클 때를 말하기는 어렵습니다.
또한 H- 통계량이 1보다 클 수 있으므로 해석이 어렵습니다.
H- 통계량은 상호 작용의 강도를 알려주지 만 상호 작용이 어떻게 생겼는지 알려주지는 않습니다.
이것이 부분 의존성 플롯 의 목적입니다.
의미있는 워크 플로는 상호 작용 강도를 측정 한 다음 관심있는 상호 작용에 대한 2D 부분 종속성 플롯을 만드는 것입니다.
입력이 픽셀 인 경우 H- 통계를 의미있게 사용할 수 없습니다.
따라서이 기술은 이미지 분류기에는 유용하지 않습니다.
상호 작용 통계는 기능을 독립적으로 섞을 수 있다는 가정하에 작동합니다.
기능이 강한 상관 관계를 보인다 면 가정을 위반하고 실제로 거의 불가능한 기능 조합을 통합 합니다.
이는 부분 의존성 플롯이 갖는 것과 동일한 문제입니다.
과대 평가 또는 과소 평가로 이어지는 지 일반적으로 말할 수 없습니다.
때로는 결과가 이상하고 작은 시뮬레이션의 경우 예상 한 결과가 나오지 않습니다 .
그러나 이것은 일화적인 관찰에 가깝습니다.
구현
이 책의 예제에서는 CRAN 및 Github 의 개발 버전에서 iml사용할 수 있는 R 패키지를 사용했습니다 .
특정 모델에 초점을 맞춘 다른 구현이 있습니다.
R 패키지 는 RuleFit 및 H- 통계를 사전 구현 합니다. R 패키지 gbm 은 경사 부스트 모델과 H- 통계를 구현합니다.
대안
H- 통계는 상호 작용을 측정하는 유일한 방법이 아닙니다.
Hooker (2004) 33의 VIN (Variable Interaction Networks) 은 예측 기능을 주 효과와 기능 상호 작용으로 분해하는 접근 방식입니다.
그런 다음 기능 간의 상호 작용이 네트워크로 시각화됩니다.
불행히도 아직 사용할 수있는 소프트웨어가 없습니다.
부분 의존성 기반 기능 상호 작용 (Greenwell et al.) al (2018) 는 두 기능 간의 상호 작용을 측정합니다.
이 접근 방식은 다른 기능의 고정 된 점에 따라 한 기능의 기능 중요도 (부분 의존성 함수의 분산으로 정의 됨)를 측정합니다.
분산이 높으면 특성이 서로 상호 작용하고 0이면 상호 작용하지 않습니다.
해당 R 패키지 vip는 Github에서 사용할 수 있습니다 .
이 패키지는 부분 의존성 플롯과 기능 중요성도 다룹니다.
Friedman, Jerome H 및 Bogdan E Popescu. "규칙 앙상블을 통한 예측 학습." 응용 통계 연보. JSTOR, 916–54. (2008).
후커, 자일스. "블랙 박스 기능에서 적층 구조 발견." 지식 발견 및 데이터 마이닝에 관한 제 10 차 ACM SIGKDD 국제 컨퍼런스의 진행. (2004).
Greenwell, Brandon M., Bradley C. Boehmke 및 Andrew J. McCarthy. "간단하고 효과적인 모델 기반 변수 중요도 측정." arXiv 사전 인쇄 arXiv : 1805.04755 (2018).
순열 기능의 중요성
순열 특성 중요도는 특성 값을 순열 한 후 모델의 예측 오류 증가를 측정하여 특성과 실제 결과 간의 관계를 끊습니다.
이론
개념은 매우 간단합니다.
특성을 순열 한 후 모델의 예측 오류 증가를 계산하여 특성의 중요성을 측정합니다.
이 경우 모델이 예측을 위해 기능에 의존했기 때문에 해당 값을 섞으면 모델 오류가 증가하는 경우 기능은 "중요"합니다.
이 경우 모델이 예측을위한 기능을 무시했기 때문에 해당 값을 섞으면 모델 오류가 변경되지 않으면 기능이 "중요하지 않습니다".
순열 특성 중요도 측정은 Breiman (2001) 에서 랜덤 포레스트에 대해 도입했습니다 .
이 아이디어를 바탕으로 Fisher, Rudin, Dominici (2018) 기능 중요도의 모델에 구애받지 않는 버전을 제안하고이를 모델 의존성이라고했습니다.
또한 많은 예측 모델이 데이터를 잘 예측할 수 있다는 점을 고려하는 (모델 별) 버전과 같이 기능 중요성에 대한 고급 아이디어를 도입했습니다.
그들의 논문은 읽을 가치가 있습니다.
Fisher, Rudin 및 Dominici (2018)를 기반으로 한 순열 기능 중요도 알고리즘 :
입력 : 훈련 된 모델 f, 특징 행렬 X, 목표 벡터 y, 오류 측정 L (y, f).
- 원래 모델 오류 추정 e orig = L (y, f (X)) (예 : 평균 제곱 오차)
- 각 기능 j = 1, ..., p에 대해 다음을 수행하십시오.
- 데이터 X에서 특성 j를 순열 하여 특성 행렬 X perm 을 생성합니다. 이렇게하면 특성 j와 실제 결과 y 간의 연관성이 끊어집니다.
- 치환 된 데이터의 예측을 기반으로 오차 e perm = L (Y, f (X perm ))을 추정 합니다.
- 순열 특성 중요도 FI j = e perm / e orig를 계산 합니다. 또는 차이를 사용할 수 있습니다. FI j = e perm -e orig
- FI 내림차순으로 기능을 정렬합니다.
Fisher, Rudin 및 Dominici (2018)는 논문에서 데이터 세트를 절반으로 분할하고 특성 j를 순열하는 대신 두 절반의 특성 j 값을 교체 할 것을 제안합니다.
이것은 당신이 그것에 대해 생각한다면, 기능 j를 순열하는 것과 똑같습니다.
보다 정확한 추정을 원하면 각 인스턴스를 서로 다른 인스턴스의 특성 j 값 (자체 제외)과 쌍을 이루어 특성 j 순열의 오류를 추정 할 수 있습니다.
이렇게하면 n(n-1)순열 오류를 추정 할 수있는 크기의 데이터 세트가 제공 되며 계산 시간이 많이 걸립니다.
n(n-1)매우 정확한 추정치를 얻는 것에 대해 진지하게 생각하는 경우 에만 -method를 사용하는 것이 좋습니다 .
교육 또는 테스트 데이터에 대한 중요성을 계산해야합니까?
tl; dr : 확실한 답이 없습니다.
학습 또는 테스트 데이터에 대한 질문에 답하면 기능의 중요성에 대한 근본적인 질문이됩니다.
학습 기반 기능과 테스트 데이터 기반 기능의 차이를 이해하는 가장 좋은 방법은 "극단적 인"예입니다.
50 개의 임의 기능 (200 개 인스턴스)이 주어지면 지속적이고 임의의 대상 결과를 예측하도록 지원 벡터 머신을 훈련했습니다.
"무작위"란 목표 결과가 50 가지 기능과 무관 함을 의미합니다.
이것은 최신 복권 번호가 주어지면 내일의 기온을 예측하는 것과 같습니다.
모델이 관계를 "학습"하면 과적 합됩니다.
실제로 SVM은 훈련 데이터에 과적 합했습니다.
훈련 데이터의 평균 절대 오차 (short : mae)는 0.29이고 테스트 데이터는 0.82입니다.
이는 항상 평균 결과 0 (매 0.78)을 예측하는 최상의 모델의 오류이기도합니다.
즉, SVM 모델은 가비지입니다.
이 과적 합 된 SVM의 50 개 기능에 대해 예상되는 기능 중요도 값은 무엇입니까?
보이지 않는 테스트 데이터에 대한 성능 향상에 기여하는 기능이 없기 때문에 0입니까?
아니면 학습 된 관계가 보이지 않는 데이터로 일반화되는지 여부에 관계없이 중요도가 모델이 각 기능에 얼마나 의존 하는지를 반영해야합니까?
학습 및 테스트 데이터에 대한 기능 중요도 분포가 어떻게 다른지 살펴 보겠습니다.
이 과적 합 된 SVM의 50 개 기능에 대해 예상되는 기능 중요도 값은 무엇입니까?
보이지 않는 테스트 데이터에 대한 성능 향상에 기여하는 기능이 없기 때문에 0입니까?
아니면 학습 된 관계가 보이지 않는 데이터로 일반화되는지 여부에 관계없이 중요도가 모델이 각 기능에 얼마나 의존 하는지를 반영해야합니까?
학습 및 테스트 데이터에 대한 기능 중요도 분포가 어떻게 다른지 살펴 보겠습니다.
이 과적 합 된 SVM의 50 개 기능에 대해 예상되는 기능 중요도 값은 무엇입니까?
보이지 않는 테스트 데이터에 대한 성능 향상에 기여하는 기능이 없기 때문에 0입니까?
아니면 학습 된 관계가 보이지 않는 데이터로 일반화되는지 여부에 관계없이 중요도가 모델이 각 기능에 얼마나 의존 하는지를 반영해야합니까?
학습 및 테스트 데이터에 대한 기능 중요도 분포가 어떻게 다른지 살펴 보겠습니다.
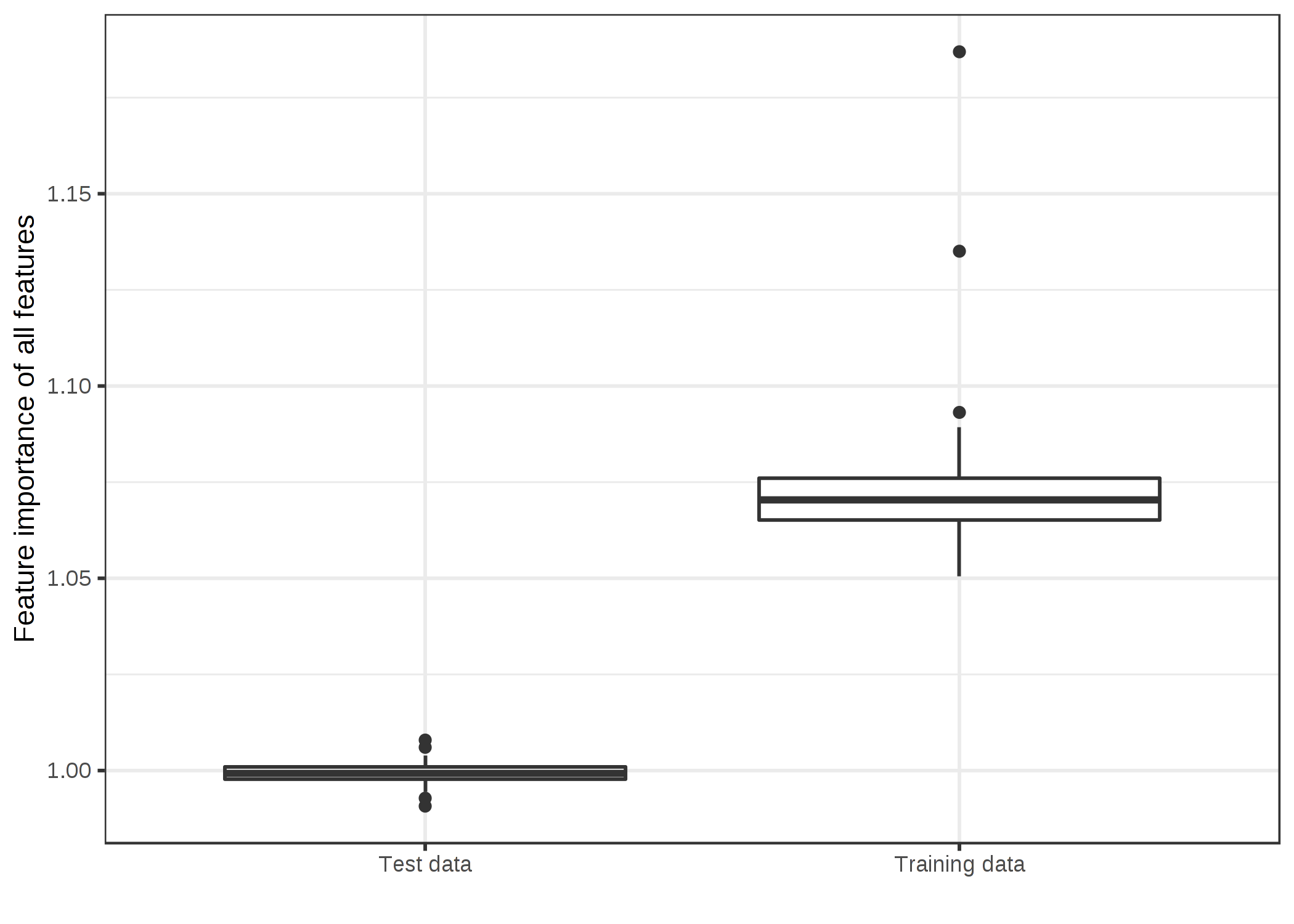
그림 5.27 : 데이터 유형별 기능 중요도 값 분포. SVM은 50 개의 임의 기능과 200 개의 인스턴스가있는 회귀 데이터 세트에서 훈련되었습니다.
SVM은 데이터를 과적 합합니다.
훈련 데이터를 기반으로 한 기능 중요도는 많은 중요한 기능을 보여줍니다.
보이지 않는 테스트 데이터에서 계산 된 기능 중요도는 1의 비율에 가깝습니다 (= 중요하지 않음).
두 가지 결과 중 어느 것이 더 바람직한지는 분명하지 않습니다.
그래서 나는 두 버전 모두에 대한 케이스를 만들고 당신이 스스로 결정하도록 노력할 것입니다.
테스트 데이터의 경우
이것은 간단한 경우입니다.
학습 데이터를 기반으로 한 모델 오류 추정은 쓰레기입니다-> 기능 중요도는 모델 오류 추정에 의존합니다-> 훈련 데이터를 기반으로 한 기능 중요도는 쓰레기입니다.
실제로 이것은 머신 러닝에서 가장 먼저 배우는 것 중 하나입니다.
모델이 학습 된 동일한 데이터에서 모델 오류 (또는 성능)를 측정하는 경우 측정은 일반적으로 너무 낙관적이며 이는 모델이 실제보다 훨씬 잘 작동합니다.
순열 기능의 중요성은 모델 오류의 측정에 의존하기 때문에 보이지 않는 테스트 데이터를 사용해야합니다.
학습 데이터를 기반으로 한 기능 중요성은 실제로 모델이 과적 합되고 기능이 전혀 중요하지 않은 경우 기능이 예측에 중요하다고 잘못 믿게 만듭니다.
훈련 데이터의 경우
훈련 데이터 사용에 대한 주장은 공식화하기가 다소 어렵지만 IMHO는 테스트 데이터 사용에 대한 주장만큼 강력합니다.
쓰레기 SVM을 다시 살펴 봅니다.
훈련 데이터에 따르면 가장 중요한 기능은 X42였습니다.
기능 X42의 부분 의존성 플롯을 살펴 보겠습니다.
부분 의존성 플롯은 모델 출력이 특징의 변화에 따라 어떻게 변하는 지 보여주고 일반화 오류에 의존하지 않습니다.
PDP가 학습 데이터로 계산되는지 테스트 데이터로 계산되는지는 중요하지 않습니다.
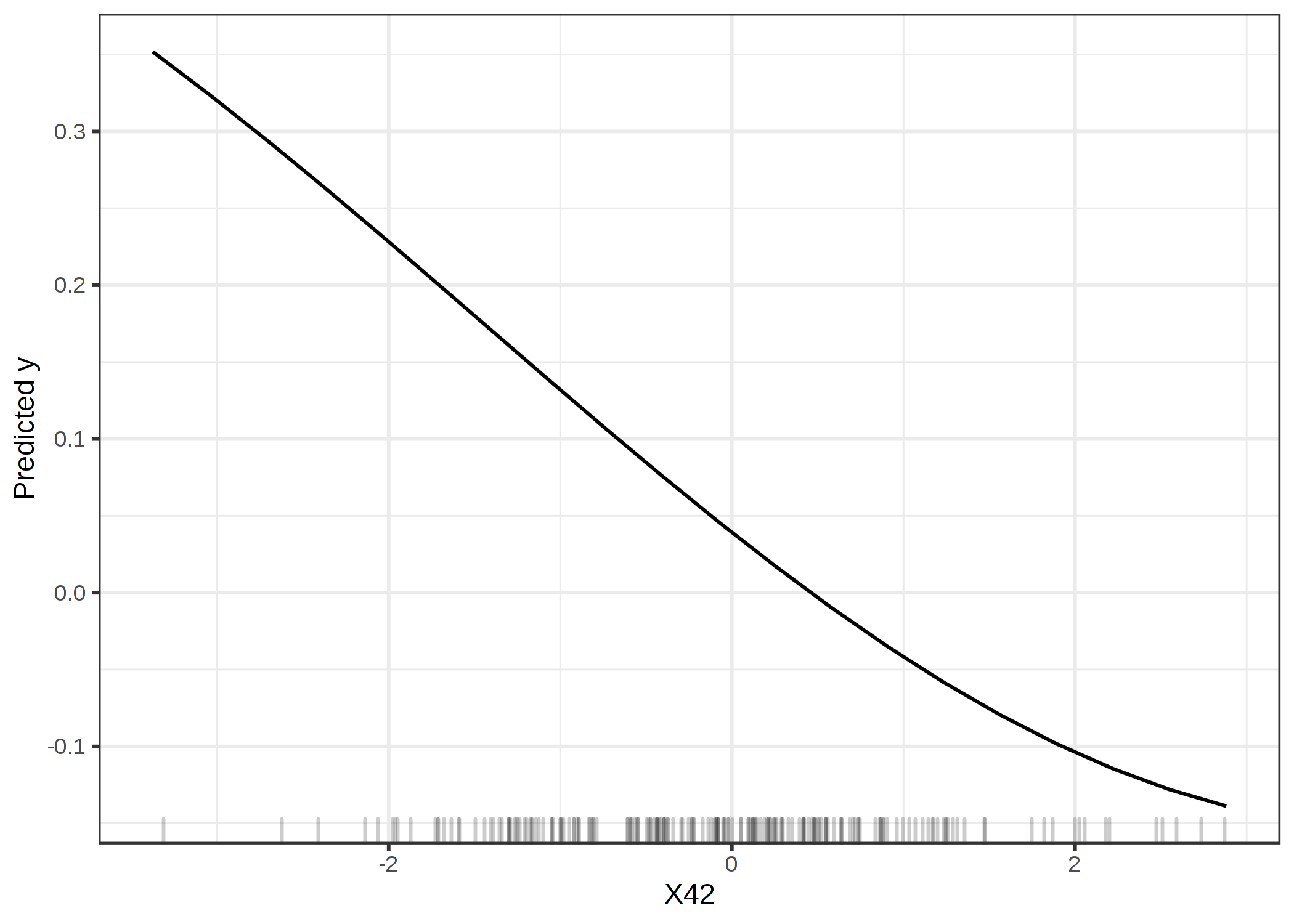
그림 5.28 : 학습 데이터를 기반으로 한 기능 중요도에 따라 가장 중요한 기능인 기능 X42의 PDP. 플롯은 SVM이이 기능에 의존하여 예측하는 방법을 보여줍니다.
플롯은 SVM이 예측을 위해 기능 X42에 의존하는 방법을 배웠 음을 분명히 보여 주지만 테스트 데이터 (1)를 기반으로 한 기능 중요도에 따라 중요하지 않습니다.
학습 데이터에 따르면 중요도는 1.19이며 모델이이 기능을 사용하는 방법을 학습했음을 반영합니다.
학습 데이터를 기반으로 한 기능 중요도는 예측을 위해 의존한다는 의미에서 모델에 중요한 기능을 알려줍니다.
훈련 데이터 사용 사례의 일환으로 테스트 데이터에 대한 주장을 소개하고 싶습니다.
실제로는 모든 데이터를 사용하여 모델을 훈련시켜 결국 가능한 최상의 모델을 얻을 수 있습니다.
이는 기능 중요도를 계산하기 위해 사용되지 않은 테스트 데이터가 남지 않음을 의미합니다.
모델의 일반화 오류를 추정 할 때 동일한 문제가 있습니다.
기능 중요도 추정을 위해 (중첩 된) 교차 검증을 사용하면 모든 데이터가 포함 된 최종 모델에서 기능 중요도가 계산되지 않고 다르게 동작 할 수있는 데이터의 하위 집합이있는 모델에서 기능 중요도가 계산된다는 문제가 있습니다.
결국 모델이 예측을 수행하기 위해 각 기능에 얼마나 의존하는지 (-> 학습 데이터) 또는 기능이 보이지 않는 데이터에 대한 모델 성능에 얼마나 기여하는지 (-> 테스트 데이터) 알고 싶은지 여부를 결정해야합니다. ). 내가 아는 한, 훈련 데이터와 테스트 데이터의 문제를 다루는 연구는 없습니다.
내 "garbage-SVM"예제보다 더 철저한 검사가 필요합니다.
더 나은 이해를 얻으려면 이러한 도구에 대한 더 많은 연구와 경험이 필요합니다.
다음으로 몇 가지 예를 살펴 보겠습니다.
저는 훈련 데이터에 대한 중요성 계산을 기반으로했습니다.
하나를 선택해야했고 훈련 데이터를 사용하면 코드가 몇 줄 더 적게 필요했기 때문입니다.
예와 해석
분류 및 회귀에 대한 예를 보여줍니다.
자궁 경부암 (분류)
자궁 경부암 을 예측하기 위해 랜덤 포레스트 모델을 적용 했습니다 .
오류 증가를 1-AUC (1-ROC 곡선 아래 영역)만큼 측정합니다.
1 배 (= 변화 없음)의 모델 오류 증가와 관련된 특징은 자궁 경부암 예측에 중요하지 않았습니다.
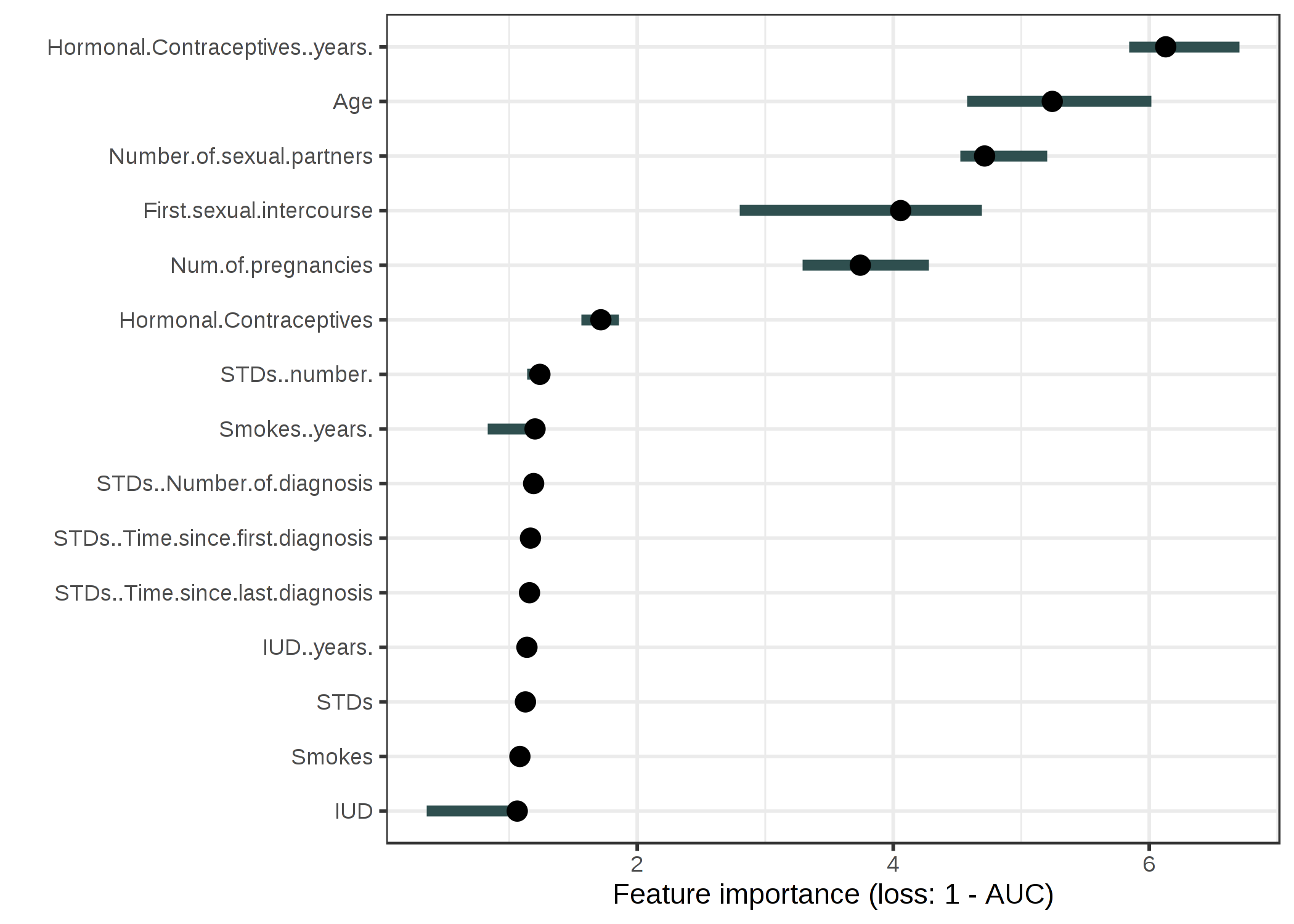
그림 5.29 : 랜덤 포레스트를 사용하여 자궁 경부암을 예측하기위한 각 기능의 중요성. 가장 중요한 특징은 Hormonal.Contraceptives..years .. Permuting Hormonal.Contraceptives..years입니다.
1-AUC가 6.13 배 증가했습니다.
가장 중요한 기능은 Hormonal.Contraceptives..years였습니다.
순열 후 6.13의 오류 증가와 관련이 있습니다.
자전거 공유 (회귀)
날씨 조건과 달력 정보를 고려 하여 임대 자전거 수 를 예측하기 위해 서포트 벡터 머신 모델을 적합합니다 .
오차 측정으로 평균 절대 오차를 사용합니다.
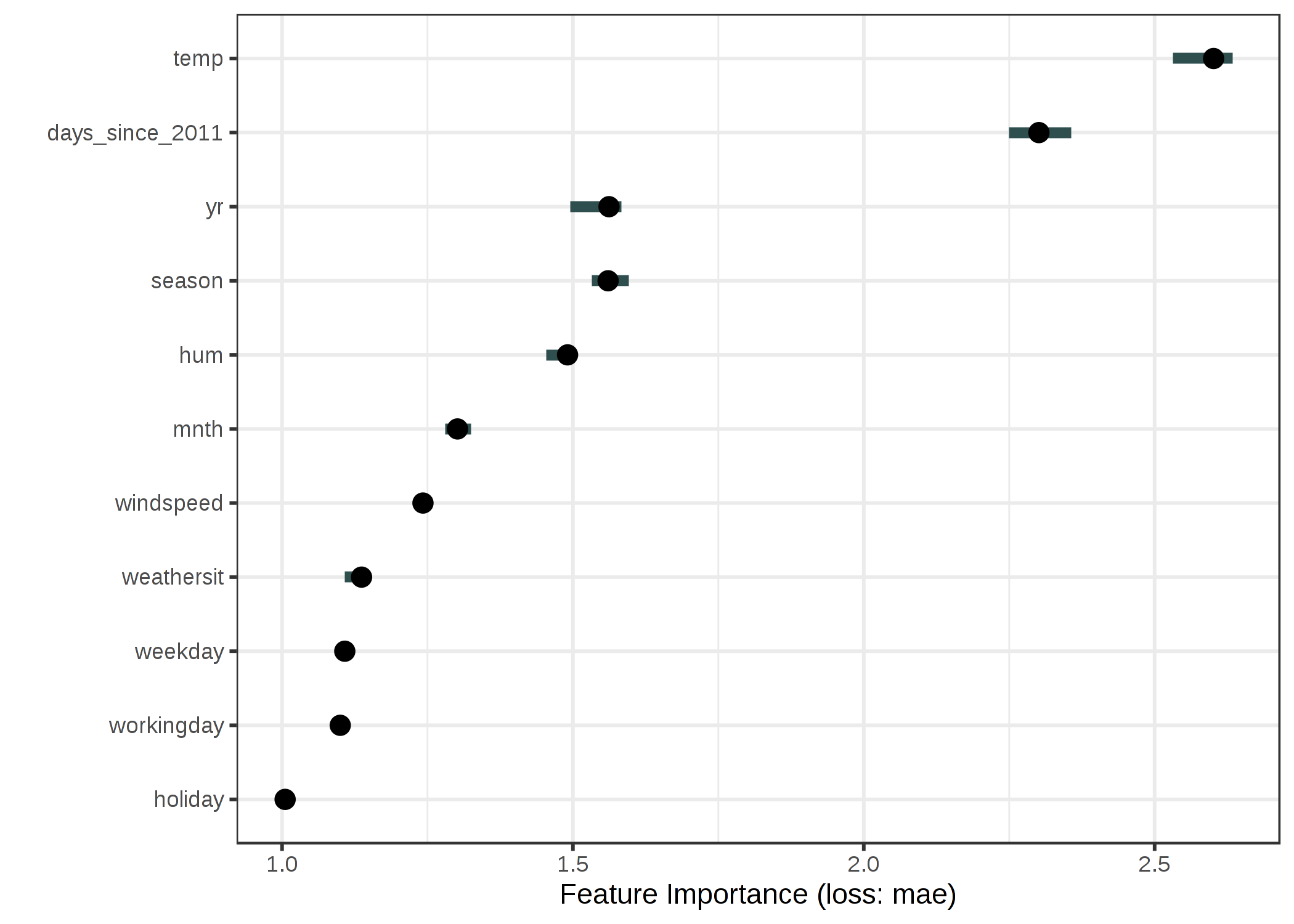
그림 5.30 : 서포트 벡터 머신을 사용하여 자전거 수를 예측할 때 각 기능의 중요성. 가장 중요한 기능은 임시 였고 가장 중요한 기능은 휴일이었습니다.
장점
좋은 해석 : 기능의 중요성은 기능의 정보가 파괴 될 때 모델 오류가 증가한다는 것입니다.
기능 중요성은 모델의 동작에 대한 고도로 압축 된 글로벌 통찰력 을 제공합니다.
오류 차이 대신 오류 비율을 사용하는 긍정적 인 측면은 기능 중요도 측정이 여러 문제에서 비교할 수 있다는 것 입니다.
중요도 측정 은 다른 기능과의 모든 상호 작용 을 자동 으로 고려 합니다.
기능을 변경하면 다른 기능과의 상호 작용 효과도 파괴됩니다.
즉, 순열 기능 중요도는 모델 성능에 대한 주요 기능 효과와 상호 작용 효과를 모두 고려합니다.
두 기능 간의 상호 작용의 중요성이 두 기능의 중요도 측정에 포함되기 때문에 이것은 또한 단점입니다.
즉, 기능 중요도가 전체 성능 저하에 합산되지는 않지만 합계가 더 큽니다.
선형 모델 에서처럼 기능간에 상호 작용이없는 경우에만 중요도가 대략적으로 합산됩니다.
순열 기능 중요도 는 모델 재교육이 필요하지 않습니다..
일부 다른 방법은 기능을 삭제하고 모델을 재교육 한 다음 모델 오류를 비교하는 것을 제안합니다.
기계 학습 모델의 재 학습에는 시간이 오래 걸릴 수 있으므로 특성을 "오직"순열하는 것만으로 많은 시간을 절약 할 수 있습니다.
특징의 하위 집합을 사용하여 모델을 재교육하는 중요도 방법은 언뜻보기에는 직관적으로 보이지만 데이터가 감소 된 모델은 기능의 중요성 때문에 의미가 없습니다.
고정 모델의 기능 중요성에 관심이 있습니다.
축소 된 데이터 세트를 사용하여 재 학습하면 관심있는 모델과 다른 모델이 생성됩니다.
가중치가 0이 아닌 고정 된 수의 특성을 사용하여 희소 선형 모델 (올가미 사용)을 학습한다고 가정합니다.
데이터 세트에는 100 개의 특성이 있으며 0이 아닌 가중치의 수를 5로 설정합니다.
가중치가 0이 아닌 특성 중 하나의 중요도를 분석합니다.
피쳐를 제거하고 모델을 다시 훈련시킵니다.
똑같이 좋은 또 다른 기능의 가중치가 0이 아니고 해당 기능이 중요하지 않다는 결론이 나오므로 모델 성능은 동일하게 유지됩니다.
또 다른 예 : 모델은 의사 결정 트리이며 첫 번째 분할로 선택된 기능의 중요성을 분석합니다.
피쳐를 제거하고 모델을 다시 훈련시킵니다.
다른 기능이 첫 번째 분할로 선택되기 때문에 전체 트리가 매우 다를 수 있습니다.
즉, 완전히 다른 트리의 오류율을 비교하여 해당 기능이 트리 중 하나에 얼마나 중요한지 결정합니다.
모델은 의사 결정 트리이며 첫 번째 분할로 선택된 기능의 중요성을 분석합니다.
피쳐를 제거하고 모델을 다시 훈련시킵니다.
다른 기능이 첫 번째 분할로 선택되기 때문에 전체 트리가 매우 다를 수 있습니다.
즉, 완전히 다른 트리의 오류율을 비교하여 해당 기능이 트리 중 하나에 얼마나 중요한지 결정합니다.
모델은 의사 결정 트리이며 첫 번째 분할로 선택된 기능의 중요성을 분석합니다.
피쳐를 제거하고 모델을 다시 훈련시킵니다.
다른 기능이 첫 번째 분할로 선택되기 때문에 전체 트리가 매우 다를 수 있습니다.
즉, 완전히 다른 트리의 오류율을 비교하여 해당 기능이 트리 중 하나에 얼마나 중요한지 결정합니다.
단점
기능 중요도를 계산하기 위해 훈련 또는 테스트 데이터 를 사용해야하는지 여부 는 매우 불분명합니다 .
순열 기능의 중요성은 모델의 오류와 관련이 있습니다 .
이것은 본질적으로 나쁘지는 않지만 어떤 경우에는 필요한 것이 아닙니다.
어떤 경우에는 성능에 대한 의미를 고려하지 않고 기능에 대해 모델의 출력이 얼마나 달라지는 지 알고 싶을 수 있습니다.
예를 들어, 누군가가 기능을 조작 할 때 모델의 출력이 얼마나 강력한 지 확인하려고합니다.
이 경우 기능이 순열 될 때 모델 성능이 얼마나 감소하는지 관심이 없지만 각 기능이 모델의 출력 분산을 얼마나 설명하는지에 관심이 없습니다.
모델 분산 (특성에 의해 설명 됨)과 특성 중요도는 모델이 잘 일반화 될 때 (즉, 과적 합하지 않음) 강한 상관 관계가 있습니다.
진정한 결과에 접근 할 수 있어야합니다 .
누군가가 모델과 레이블이 지정되지 않은 데이터 만 제공하지만 실제 결과는 제공하지 않는 경우 순열 특성 중요도를 계산할 수 없습니다.
순열 기능의 중요성은 측정에 임의성을 추가하는 기능을 섞는 방법에 따라 달라집니다.
순열이 반복되면 결과가 크게 달라질 수 있습니다 .
순열을 반복하고 반복에 대한 중요도 측정 값을 평균화하면 측정 값이 안정화되지만 계산 시간이 늘어납니다.
특성이 상관 관계가있는 경우 순열 특성 중요도 가 비현실적인 데이터 인스턴스에 의해 편향 될 수 있습니다 .
특성의 순열은 둘 이상의 특성이 상호 연관 될 때 예상치 못한 데이터 인스턴스를 생성합니다.
양의 상관 관계 (예 : 사람의 키와 몸무게)가 있고 기능 중 하나를 섞으면 물리적으로 불가능하거나 가능성이없는 새 인스턴스 (예 : 30kg 무게의 2 미터 사람)를 생성하지만 이러한 새 인스턴스를 사용합니다.
중요성을 측정합니다.
즉, 상관 특성의 순열 특성 중요도에 대해 특성을 실제로 관찰 할 수없는 값으로 교환 할 때 모델 성능이 얼마나 저하되는지 고려합니다.
기능이 강한 상관 관계가 있는지 확인하고 기능 중요도 해석에주의하십시오.
또 다른 까다로운 점 : 상관 기능을 추가하면 관련 기능의 중요성이 낮아질 수 있습니다.
두 기능의 중요성을 분할하여 "분할"기능의 중요성에 대한 예를 들어 보겠습니다.
비가 올 확률을 예측하고 전날 오전 8시의 온도를 다른 관련없는 기능과 함께 기능으로 사용하려고합니다.
나는 무작위 숲을 훈련하고 온도가 가장 중요한 특징이며 모든 것이 잘되고 다음날 밤에 잘자는 것이 밝혀졌습니다.
이제 오전 8시의 온도와 강한 상관 관계가있는 기능으로 오전 9시의 온도를 추가로 포함하는 또 다른 시나리오를 상상해보십시오. 오전 8시의 온도를 이미 알고 있다면 오전 9시의 온도는 많은 추가 정보를 제공하지 않습니다.
하지만 더 많은 기능을 갖는 것이 항상 좋습니다.
두 가지 온도 특성과 상관 관계가없는 특성을 사용하여 무작위 숲을 훈련합니다.
무작위 숲의 일부 나무는 오전 8시 온도를, 다른 나무는 오전 9시 온도를, 또 다른 나무는 모두 다른 나무는 없습니다.
두 가지 온도 기능은 이전의 단일 온도 기능보다 약간 더 중요하지만 중요한 기능 목록의 맨 위에있는 대신 각 온도는 이제 중간 어딘가에 있습니다.
상관 관계가있는 기능을 도입함으로써 저는 중요도 사다리의 최상위에서 평범함으로 가장 중요한 기능을 걷어 냈습니다.
한편으로 이것은 기본 머신 러닝 모델, 여기서 랜덤 포레스트의 동작을 단순히 반영하기 때문에 괜찮습니다.
8:00 AM 온도는 모델이 이제 9:00 AM 측정에도 의존 할 수 있기 때문에 덜 중요해졌습니다.
반면에 기능 중요성의 해석을 훨씬 더 어렵게 만듭니다.
측정 오류에 대한 기능을 확인한다고 가정 해보십시오.
수표는 비용이 많이 들고 가장 중요한 기능 중 상위 3 개만 확인하기로 결정합니다.
첫 번째 경우에는 온도를 확인하고 두 번째 경우에는 중요도를 공유하기 때문에 온도 기능을 포함하지 않습니다.
중요도 값은 모델 동작 수준에서 의미가있을 수 있지만 상관 된 기능이있는 경우 혼란 스럽습니다.
소프트웨어 및 대안
iml예제 에는 R 패키지가 사용되었습니다. 는 R 패키지 DALEX및 vip뿐만 아니라 파이썬 라이브러리 alibi, scikit-learn그리고 rfpimp, 또한 모델에 독립적 순열 기능의 중요성을 구현합니다.
PIMP 라는 알고리즘 은 기능 중요도 알고리즘을 조정하여 중요도에 대한 p- 값을 제공합니다.
- Breiman, Leo. "Random Forests." 기계 학습 45 (1). Springer : 5-32 (2001).
- Fisher, Aaron, Cynthia Rudin 및 Francesca Dominici. "모델 클래스 신뢰도 : 'Rashomon'관점에서 모든 기계 학습 모델 클래스에 대한 가변 중요성 측정." http://arxiv.org/abs/1801.01489(2018 )
글로벌 대리
글로벌 대리 모델은 블랙 박스 모델의 예측에 근접하도록 훈련 된 해석 가능한 모델입니다.
대리 모델을 해석하여 블랙 박스 모델에 대한 결론을 도출 할 수 있습니다.
더 많은 기계 학습을 사용하여 기계 학습 해석 가능성을 해결하십시오!
이론
대리 모델은 엔지니어링에도 사용됩니다.
관심있는 결과가 비싸거나 시간이 많이 걸리거나 측정하기 어려운 경우 (예 : 복잡한 컴퓨터 시뮬레이션에서 비롯된 경우), 결과의 저렴하고 빠른 대리 모델을 대신 사용할 수 있습니다.
엔지니어링과 해석 가능한 기계 학습에서 사용되는 대리 모델의 차이점은 기본 모델이 시뮬레이션이 아닌 기계 학습 모델이고 대리 모델이 해석 가능해야한다는 것입니다. (해석 가능한)
대리 모델의 목적은 기본 모델의 예측을 가능한 한 정확하게 추정하고 동시에 해석 할 수 있도록하는 것입니다.
대리 모델의 아이디어는 근사 모델, 메타 모델, 반응 표면 모델, 에뮬레이터 등 다른 이름으로 찾을 수 있습니다.
이론 정보 : 실제로 대리 모델을 이해하는 데 필요한 이론은 많지 않습니다.
우리는 g가 해석 가능하다는 제약 하에서 대리 모델 예측 함수 g를 사용하여 블랙 박스 예측 함수 f를 가능한 한 가깝게 근사하려고합니다.
기능 g의 경우 모든 해석 가능한 모델 (예 : 해석 가능한 모델 장)을 사용할 수 있습니다.
예를 들어 선형 모델 :
g(x)=β0+β1x1+…+βpxp
또는 의사 결정 트리 :
g(x)=∑m=1McmI{x∈Rm}
대리 모델 학습은 블랙 박스 모델의 내부 동작에 대한 정보가 필요하지 않고 데이터 및 예측 기능에 대한 액세스 만 필요하기 때문에 모델에 구애받지 않는 방법입니다.
기본 기계 학습 모델이 다른 모델로 대체 된 경우에도 대리 방법을 사용할 수 있습니다.
블랙 박스 모델 유형과 대리 모델 유형의 선택이 분리됩니다.
대리 모델을 얻으려면 다음 단계를 수행하십시오.
- 데이터 세트 X를 선택합니다. 이는 블랙 박스 모델 학습에 사용 된 동일한 데이터 세트이거나 동일한 분포의 새 데이터 세트 일 수 있습니다. 애플리케이션에 따라 데이터의 하위 집합 또는 포인트 그리드를 선택할 수도 있습니다.
- 선택한 데이터 세트 X에 대해 블랙 박스 모델의 예측을 가져옵니다.
- 해석 가능한 모델 유형 (선형 모델, 의사 결정 트리 등)을 선택하십시오.
- 데이터 세트 X 및 해당 예측에 대해 해석 가능한 모델을 학습시킵니다.
- 축하합니다! 이제 대리 모델이 있습니다.
- 대리 모델이 블랙 박스 모델의 예측을 얼마나 잘 복제하는지 측정합니다.
- 대리 모델을 해석합니다.
몇 가지 추가 단계가 있거나 약간 다른 대리 모델에 대한 접근 방식을 찾을 수 있지만 일반적인 아이디어는 일반적으로 여기에 설명 된 것과 같습니다.
대리자가 블랙 박스 모델을 얼마나 잘 복제하는지 측정하는 한 가지 방법은 R- 제곱 측정입니다.
R2=1−SSESST=1−∑i=1n(y^∗(i)−y^(i))2∑i=1n(y^(i)−y^¯)2
여기서 대리 모델의 i 번째 인스턴스에 대한 예측이다 의 예측 블랙 박스 모델 및 블랙 박스 모델 예측의 평균 . SSE는 제곱합 오차를 나타내고 SST는 제곱합 합계를 나타냅니다.
R- 제곱 측도는 대리 모델에서 캡처 한 분산의 백분율로 해석 할 수 있습니다.
R- 제곱이 1에 가까우면 (= SSE가 낮음) 해석 가능한 모델은 블랙 박스 모델의 동작에 매우 근접합니다.
해석 가능한 모델이 매우 가까운 경우 복잡한 모델을 해석 가능한 모델로 대체 할 수 있습니다. R- 제곱이 0에 가까우면 (= 높은 SSE) 해석 가능한 모델은 블랙 박스 모델을 설명하지 못합니다.y^∗(i)y^(i)y^¯
기본 블랙 박스 모델의 모델 성능, 즉 실제 결과를 예측하는 데 얼마나 좋은지 나쁜지에 대해서는 언급하지 않았습니다.
블랙 박스 모델의 성능은 대리 모델을 훈련하는 데 중요한 역할을하지 않습니다.
대리 모델의 해석은 실제 세계가 아닌 모델에 대한 진술을하기 때문에 여전히 유효합니다.
그러나 블랙 박스 모델 자체가 무관하기 때문에 블랙 박스 모델이 나쁘면 대리 모형의 해석은 무의미 해집니다.
또한 원본 데이터의 하위 집합을 기반으로 대리 모델을 구축하거나 인스턴스의 가중치를 조정할 수도 있습니다.
이런 식으로 우리는 해석의 초점을 변경하는 대리 모델의 입력 분포를 변경합니다 (그러면 더 이상 실제로 전역 적이 지 않습니다).
데이터의 특정 인스턴스를 기준으로 데이터에 로컬 가중치를 부여하면 (인스턴스가 선택한 인스턴스에 가까울수록 가중치가 높아짐) 인스턴스의 개별 예측을 설명 할 수있는 로컬 대리 모델을 얻습니다.
다음 장 에서 지역 모델에 대해 자세히 알아보십시오 .
예
대리 모델을 설명하기 위해 회귀 및 분류 예를 고려합니다.
첫째, 날씨와 달력 정보 를 바탕으로 일일 임대 자전거 수 를 예측하는 서포트 벡터 머신을 훈련합니다 .
서포트 벡터 머신은 그다지 해석 할 수 없기 때문에 CART 의사 결정 트리를 해석 가능한 모델로 사용하여 서로 게이트를 훈련하여 서포트 벡터 머신의 동작을 근사합니다.
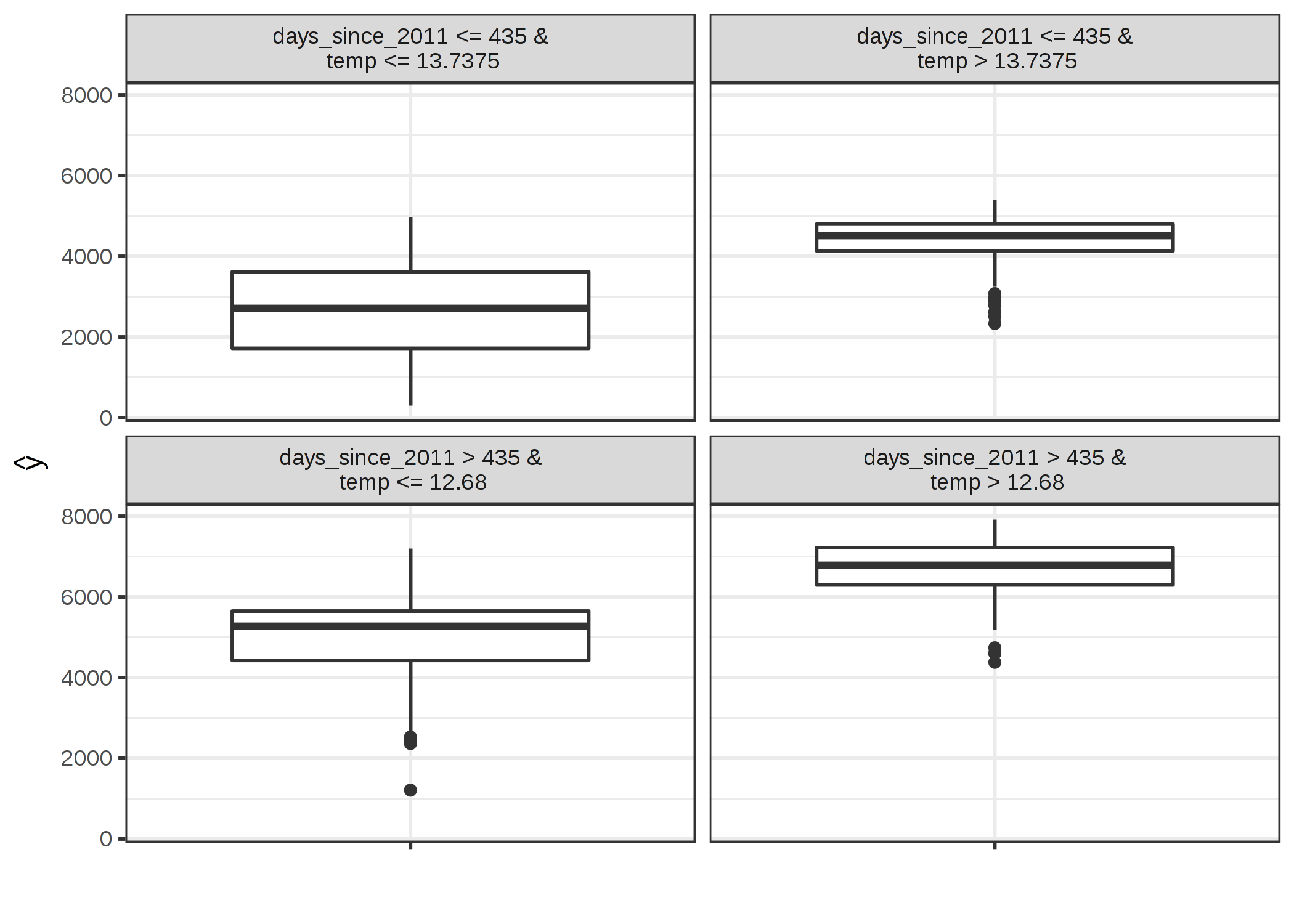
그림 5.31 : 자전거 대여 데이터 세트에서 훈련 된 지원 벡터 머신의 예측에 가까운 대리 트리의 터미널 노드. 노드의 분포는 대리 트리가 온도가 섭씨 13도를 초과 할 때와 그날이 2 년 기간 (435 일의 절단 지점)이 늦을 때 더 많은 대여 자전거를 예측한다는 것을 보여줍니다.
대리 모델의 R- 제곱 (분산 설명)은 0.77입니다. 즉, 기본 블랙 박스 동작에 매우 가깝지만 완벽하지는 않습니다.
적합이 완벽하다면 서포트 벡터 머신을 버리고 대신 트리를 사용할 수 있습니다.
두 번째 예에서는 임의의 포리스트를 사용하여 자궁 경부암 의 확률을 예측합니다 .
다시 원래 데이터 세트로 의사 결정 트리를 훈련하지만 데이터의 실제 클래스 (건강한 대 암) 대신 무작위 포리스트를 결과로 예측합니다.
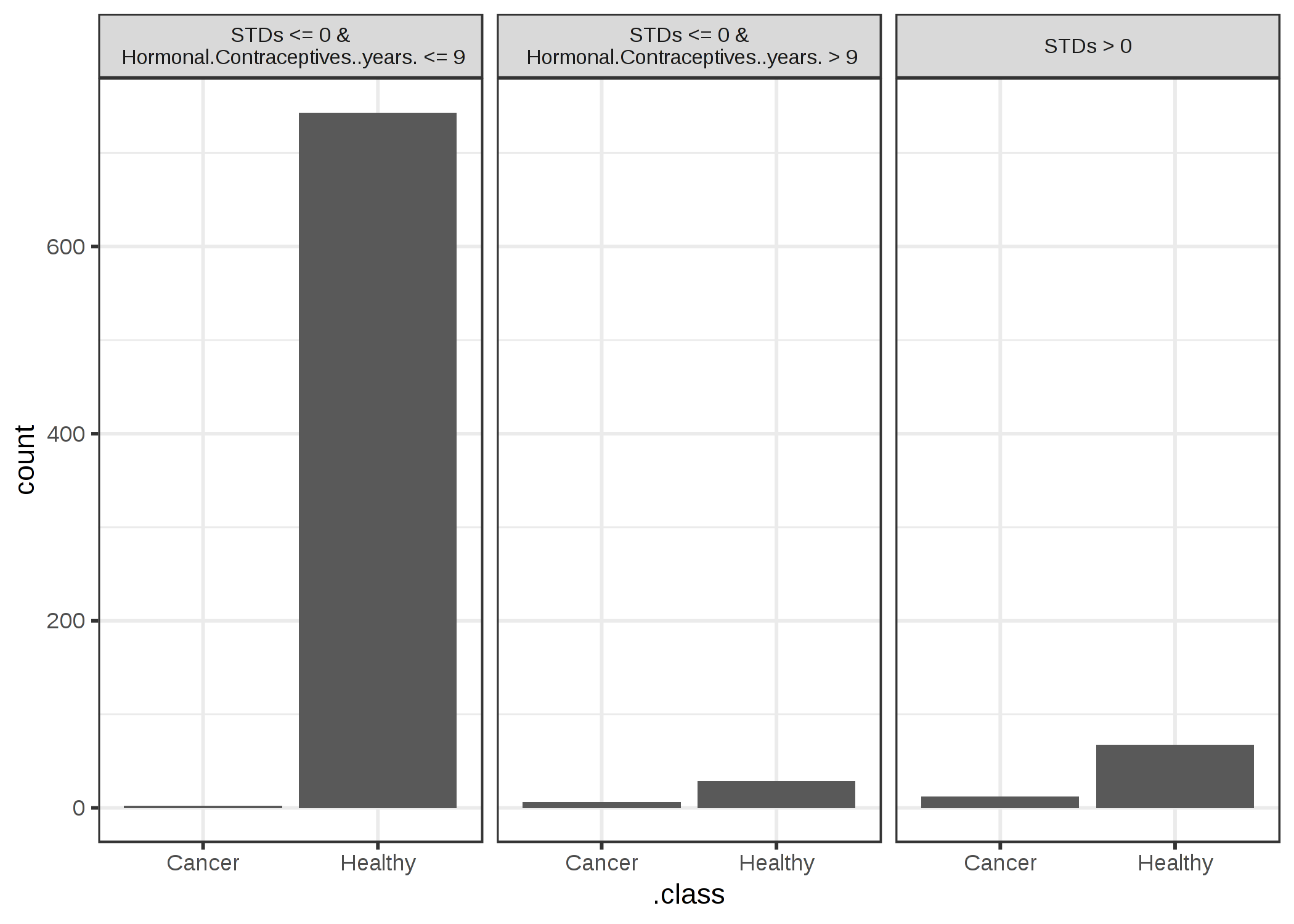
그림 5.32 : 자궁 경부암 데이터 세트에서 훈련 된 임의의 숲의 예측에 가까운 대리 트리의 터미널 노드. 노드의 개수는 노드에서 블랙 박스 모델 분류의 빈도를 보여줍니다.
대리 모델의 R- 제곱 (분산 설명)은 0.19입니다.
즉, 랜덤 포레스트에 근접하지 않으며 복잡한 모델에 대한 결론을 도출 할 때 트리를 과도하게 해석해서는 안됩니다.
장점
대리 모델 방법은 유연합니다 . 해석 가능한 모델 장의 모든 모델을 사용할 수 있습니다.
이것은 해석 가능한 모델뿐만 아니라 기본 블랙 박스 모델도 교환 할 수 있음을 의미합니다.
복잡한 모델을 만들어 회사의 여러 팀에 설명한다고 가정 해 보겠습니다.
한 팀은 선형 모델에 익숙하고 다른 팀은 의사 결정 트리를 이해할 수 있습니다.
원래 블랙 박스 모델에 대해 두 가지 대리 모델 (선형 모델 및 의사 결정 트리)을 훈련하고 두 가지 종류의 설명을 제공 할 수 있습니다.
더 나은 성능의 블랙 박스 모델을 찾으면 동일한 클래스의 대리 모델을 사용할 수 있으므로 해석 방법을 변경할 필요가 없습니다.
나는 접근 방식이 매우 직관적 이고 간단 하다고 주장합니다 . 즉, 구현하기 쉽지만 데이터 과학이나 기계 학습에 익숙하지 않은 사람들에게도 쉽게 설명 할 수 있습니다.
R- 제곱 측정 값을 사용하면 대리 모델이 블랙 박스 예측에 얼마나 좋은지 쉽게 측정 할 수 있습니다.
단점
대리 모델은 실제 결과를 볼 수 없기 때문에 데이터가 아니라 모델에 대한 결론을 도출 한다는 점을 알고 있어야합니다 .
대리 모델이 블랙 박스 모델에 충분히 가깝다는 확신을 갖기 위해 R- 제곱에 대한 최상의 컷오프가 무엇인지는 명확하지 않습니다 . 분산의 80 %가 설명 되었습니까? 50 %? 99 %?
대리 모델이 블랙 박스 모델에 얼마나 가까운 지 측정 할 수 있습니다.
우리가 아주 가깝지는 않지만 충분히 가깝다고 가정합시다.
해석 가능한 모델이 데이터 세트의 한 하위 집합에 대해서는 매우 가깝지만 다른 하위 집합에 대해서는 광범위하게 다를 수 있습니다.
이 경우 단순 모델에 대한 해석이 모든 데이터 포인트에 대해 똑같이 좋지는 않습니다.
대리자로 선택한 해석 가능한 모델 에는 모든 장점과 단점이 있습니다.
어떤 사람들은 일반적으로 본질적으로 해석 가능한 모델 (선형 모델 및 의사 결정 트리 포함)이 없으며 해석 가능성에 대한 환상을 갖는 것이 위험 할 것이라고 주장합니다.
이 의견을 공유한다면 당연히이 방법은 당신을위한 것이 아닙니다.
소프트웨어
iml예제로 R 패키지를 사용했습니다 .
기계 학습 모델을 학습 할 수 있다면 대리 모델을 직접 구현할 수 있어야합니다.
해석 가능한 모델을 훈련하여 블랙 박스 모델의 예측을 예측하기 만하면됩니다.
로컬 대리 (LIME)
로컬 대리 모델은 블랙 박스 머신 러닝 모델의 개별 예측을 설명하는 데 사용되는 해석 가능한 모델입니다.
지역 해석 가능한 모델 불가지론 적 설명 (LIME) 은 저자가 지역 대리 모델의 구체적인 구현을 제안하는 논문입니다.
대리 모델은 기본 블랙 박스 모델의 예측을 근사하도록 훈련됩니다.
LIME는 글로벌 대리 모델을 교육하는 대신 개별 예측을 설명하기 위해 로컬 대리 모델을 교육하는 데 중점을 둡니다.
아이디어는 매우 직관적입니다.
먼저 훈련 데이터는 잊어 버리고 데이터 포인트를 입력하고 모델의 예측을 얻을 수있는 블랙 박스 모델 만 있다고 상상해보십시오. 원하는만큼 자주 상자를 조사 할 수 있습니다.
목표는 머신 러닝 모델이 특정 예측을 한 이유를 이해하는 것입니다.
LIME은 데이터 변형을 기계 학습 모델에 제공 할 때 예측에 어떤 일이 발생하는지 테스트합니다.
LIME은 교란 된 샘플과 블랙 박스 모델의 해당 예측으로 구성된 새로운 데이터 세트를 생성합니다.
그런 다음이 새로운 데이터 세트에서 LIME은 해석 가능한 모델을 학습시키고, 이는 샘플 인스턴스와 관심있는 인스턴스의 근접성에 의해 가중치가 부여됩니다.
해석 가능한 모델은 해석 가능한 모델 장에 있는 모든 것이 될 수 있습니다 ( 예 : Lasso).또는 의사 결정 트리 .
학습 된 모델은 로컬에서 머신 러닝 모델 예측의 좋은 근사치 여야하지만 좋은 글로벌 근사치 일 필요는 없습니다.
이러한 종류의 정확도를 로컬 충실도라고도합니다.
수학적으로 해석 가능성 제약이있는 로컬 대리 모델은 다음과 같이 표현할 수 있습니다.
explanation(x)=argming∈GL(f,g,πx)+Ω(g)
예 x에 대한 설명 모델은 손실 L (예 : 평균 제곱 오차)을 최소화하는 모델 g (예 : 선형 회귀 모델)로, 설명이 원래 모델 f (예 : xgboost 모델)의 예측에 얼마나 가까운지를 측정합니다.
모델 복잡성 Ω(g)낮게 유지됩니다 (예 : 더 적은 기능 선호). G는 가능한 설명의 집합입니다 (예 : 가능한 모든 선형 회귀 모델).
근접 측정πx설명을 위해 고려하는 인스턴스 x 주변의 이웃 크기를 정의합니다.
실제로 LIME은 손실 부분 만 최적화합니다.
사용자는 예를 들어 선형 회귀 모델이 사용할 수있는 최대 기능 수를 선택하여 복잡성을 결정해야합니다.
로컬 대리 모델 훈련을위한 레시피 :
- 블랙 박스 예측에 대한 설명이 필요한 관심 인스턴스를 선택합니다.
- 데이터 세트를 교란하고 이러한 새로운 포인트에 대한 블랙 박스 예측을 얻습니다.
- 관심있는 인스턴스에 대한 근접성에 따라 새 샘플에 가중치를 부여합니다.
- 변형이있는 데이터 세트에서 가중되고 해석 가능한 모델을 학습시킵니다.
- 지역 모델을 해석하여 예측을 설명하십시오.
예를 들어 R 및 Python 의 현재 구현에서는 해석 가능한 대리 모델로 선형 회귀를 선택할 수 있습니다.
미리 해석 가능한 모델에 포함 할 기능 수인 K를 선택해야합니다.
K가 낮을수록 모델을 해석하기가 더 쉽습니다.
더 높은 K는 잠재적으로 더 높은 충실도의 모델을 생성합니다.
정확히 K 개의 특성을 사용하여 모델을 학습시키는 방법에는 여러 가지가 있습니다.
좋은 선택은 Lasso 입니다.
정규화 매개 변수가 높은 Lasso 모델λ기능이없는 모델을 생성합니다.
천천히 감소하는 Lasso 모델을 재교육함으로써λ, 차례로 기능은 0과 다른 가중치 추정치를 얻습니다.
모델에 K 개의 피쳐가 있으면 원하는 피쳐 수에 도달 한 것입니다.
다른 전략은 기능의 정방향 또는 역방향 선택입니다.
즉, 전체 모델 (= 모든 기능 포함) 또는 절편 만있는 모델로 시작한 다음 K 기능이있는 모델에 도달 할 때까지 추가 또는 제거 할 때 가장 큰 개선을 가져올 기능을 테스트합니다.
데이터의 변형을 어떻게 얻습니까? 이는 텍스트, 이미지 또는 표 형식 데이터 일 수있는 데이터 유형에 따라 다릅니다.
텍스트 및 이미지의 경우 솔루션은 단일 단어 또는 슈퍼 픽셀을 켜거나 끄는 것입니다.
표 형식 데이터의 경우 LIME는 각 기능을 개별적으로 섭동하여 기능에서 가져온 평균 및 표준 편차를 사용하는 정규 분포에서 추출하여 새 샘플을 만듭니다.
테이블 형식 데이터 용 LIME
테이블 형식 데이터는 각 행이 인스턴스를 나타내고 각 열이 기능을 나타내는 테이블로 제공되는 데이터입니다.
LIME 샘플은 관심있는 인스턴스 주변이 아니라 문제가되는 훈련 데이터의 질량 중심에서 가져옵니다.
그러나 일부 샘플 포인트 예측에 대한 결과가 관심 데이터 포인트와 다르고 LIME이 최소한 몇 가지 설명을 배울 수있는 확률을 높입니다.
샘플링 및 로컬 모델 학습이 작동하는 방식을 시각적으로 설명하는 것이 가장 좋습니다.
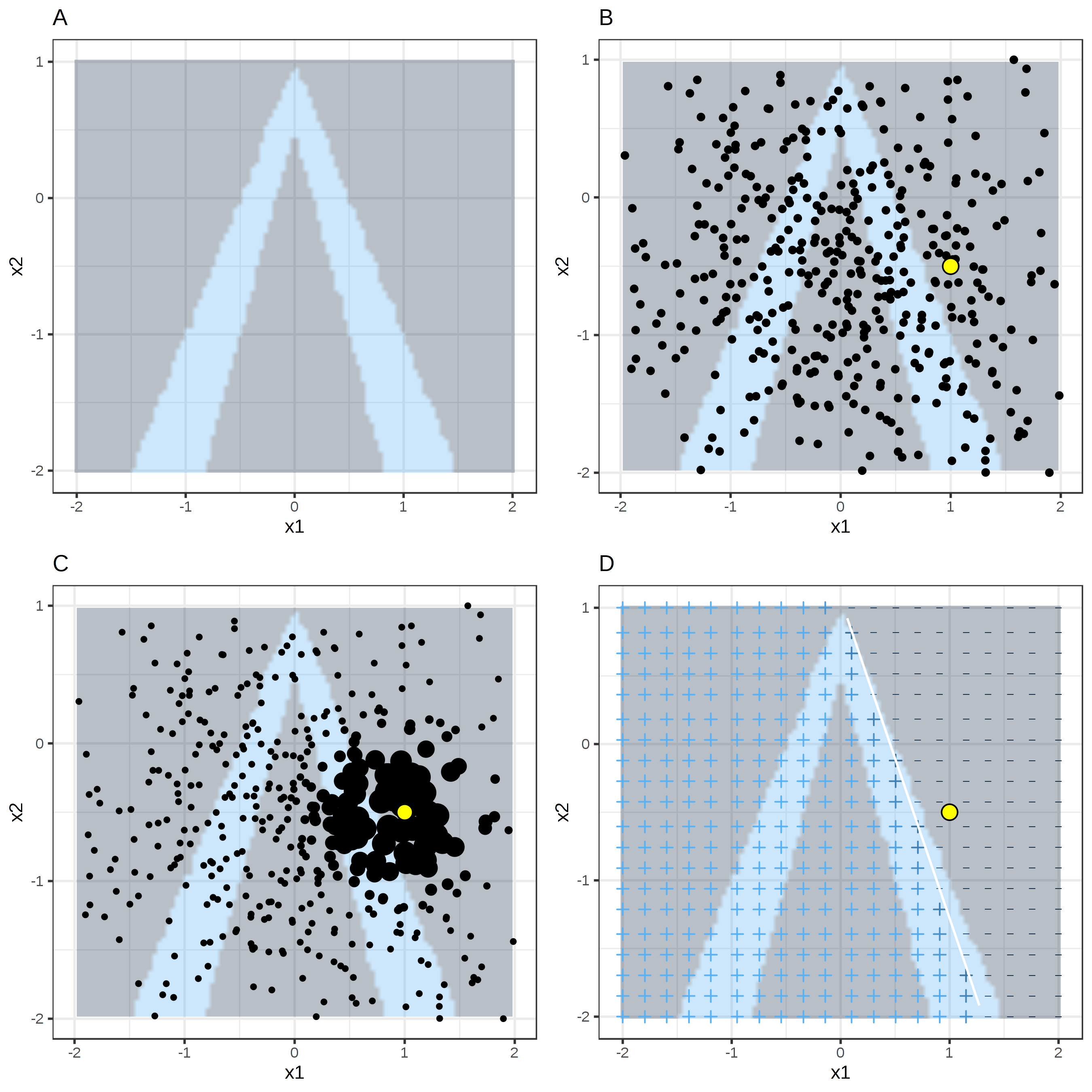
그림 5.33 : 표 형식 데이터에 대한 LIME 알고리즘. A) 특성 x1 및 x2가 주어진 랜덤 포레스트 예측. 예상 클래스 : 1 (어두움) 또는 0 (밝음). B) 관심 인스턴스 (큰 점) 및 정규 분포에서 샘플링 된 데이터 (작은 점). C) 관심 인스턴스 근처의 포인트에 더 높은 가중치를 할당합니다. D)
그리드의 기호는 가중치가 적용된 샘플에서 로컬로 학습 된 모델의 분류를 보여줍니다.
흰색 선은 결정 경계를 표시합니다 (P (class = 1) = 0.5).
항상 그렇듯이 악마는 세부 사항에 있습니다. 한 지점 주변에 의미있는 이웃을 정의하는 것은 어렵습니다.
LIME은 현재 지수 평활 커널을 사용하여 이웃을 정의합니다.
평활 커널은 두 개의 데이터 인스턴스를 가져와 근접 측정 값을 반환하는 함수입니다.
커널 너비는 이웃의 크기를 결정합니다. 커널 너비가 작 으면 인스턴스가 로컬 모델에 영향을주기 위해 매우 가까워 야 함을 의미하고, 커널 너비가 클수록 더 멀리있는 인스턴스도 모델에 영향을 미칩니다.
LIME의 Python 구현 을 보면 (lime / lime_tabular.py 파일)(정규화 된 데이터에서) 지수 평활 커널을 사용하고 커널 너비가 학습 데이터 열 수의 제곱근의 0.75 배임을 알 수 있습니다.
순진한 코드 라인처럼 보이지만 거실에 조부모님에게서받은 좋은 도자기 옆에 앉아있는 코끼리와 같습니다.
가장 큰 문제는 최적의 커널이나 너비를 찾을 수있는 좋은 방법이 없다는 것입니다.
그리고 0.75는 어디에서 왔습니까? 특정 시나리오에서는 다음 그림과 같이 커널 너비를 변경하여 쉽게 설명을 바꿀 수 있습니다.
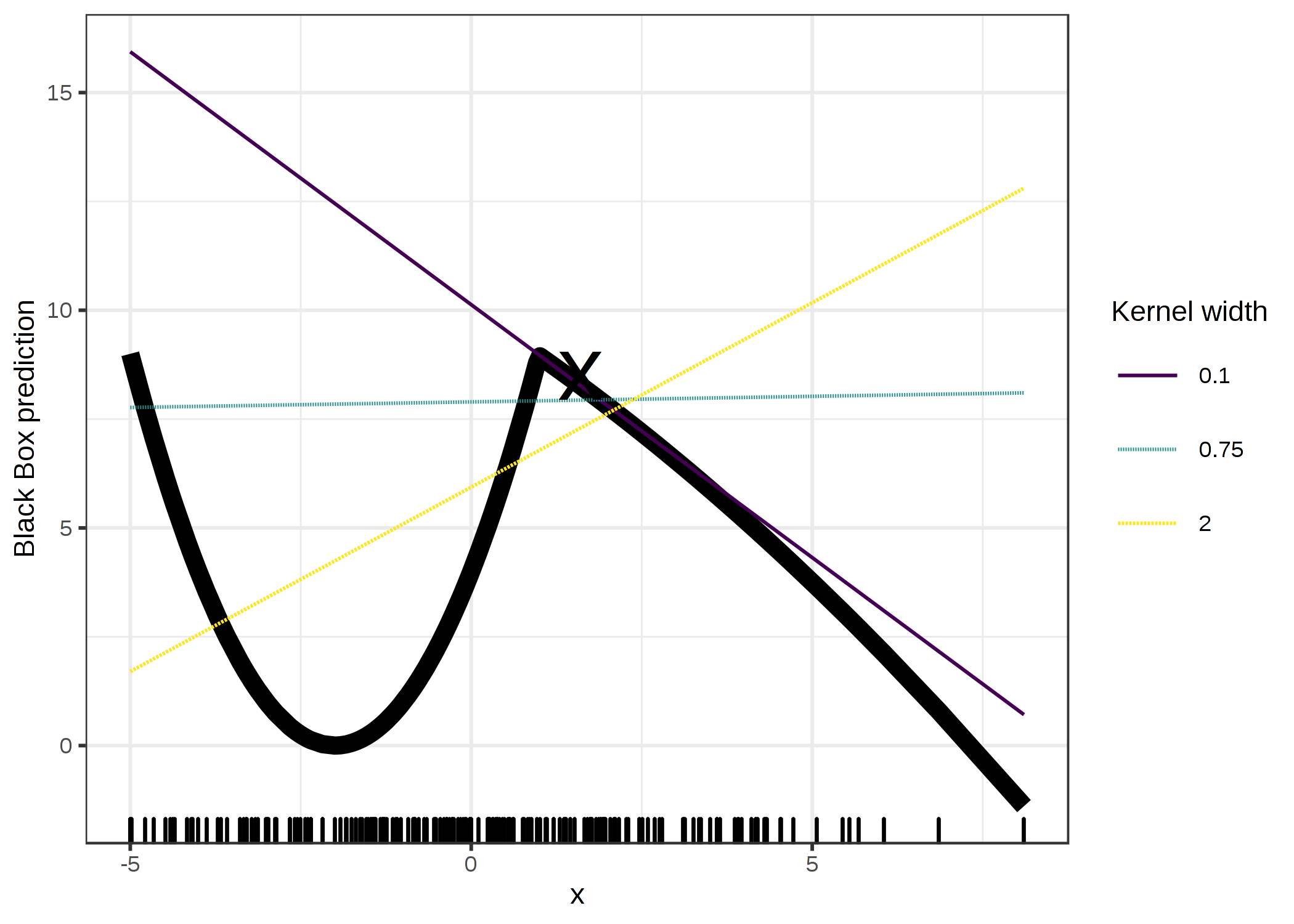
그림 5.34 : 인스턴스 x = 1.6의 예측 설명. 단일 특성에 따른 블랙 박스 모델의 예측은 굵은 선으로 표시되고 데이터 분포는 러그로 표시됩니다.
커널 너비가 다른 세 개의 로컬 대리 모델이 계산됩니다.
결과 선형 회귀 모델은 커널 너비에 따라 달라집니다. 특성이 x = 1.6에 대해 음수, 양수 또는 효과가 없습니까?
이 예는 하나의 기능 만 보여줍니다. 고차원 적 특징 공간에서는 악화됩니다.
거리 측정이 모든 기능을 동일하게 처리해야하는지 여부도 매우 불분명합니다.
기능 x1의 거리 단위가 기능 x2의 한 단위와 동일합니까? 거리 측정은 매우 임의적이며 다른 차원 (특징이라고도 함)의 거리는 전혀 비교할 수 없습니다.
예
구체적인 예를 살펴 보겠습니다.
우리는 자전거 대여 데이터 로 돌아가서 예측 문제를 분류로 전환합니다.
자전거 대여가 시간이 지남에 따라 인기가 높아지는 추세를 고려한 후 특정 날에 대여 한 자전거 수가 얼마나 될지 알고 싶습니다.
추세선 위 또는 아래. 또한 "위"는 평균 자전거 수를 초과하는 것으로 해석 할 수 있지만 추세에 맞게 조정됩니다.
먼저 분류 작업에서 100 개의 나무가있는 랜덤 포레스트를 훈련합니다.
날씨 및 달력 정보를 기준으로 볼 때 자전거 대여 대수가 추세없는 평균을 초과하는 날은 언제입니까?
설명은 2 가지 기능으로 작성됩니다. 예측 된 클래스가 다른 두 인스턴스에 대해 학습 된 희소 지역 선형 모델의 결과 :
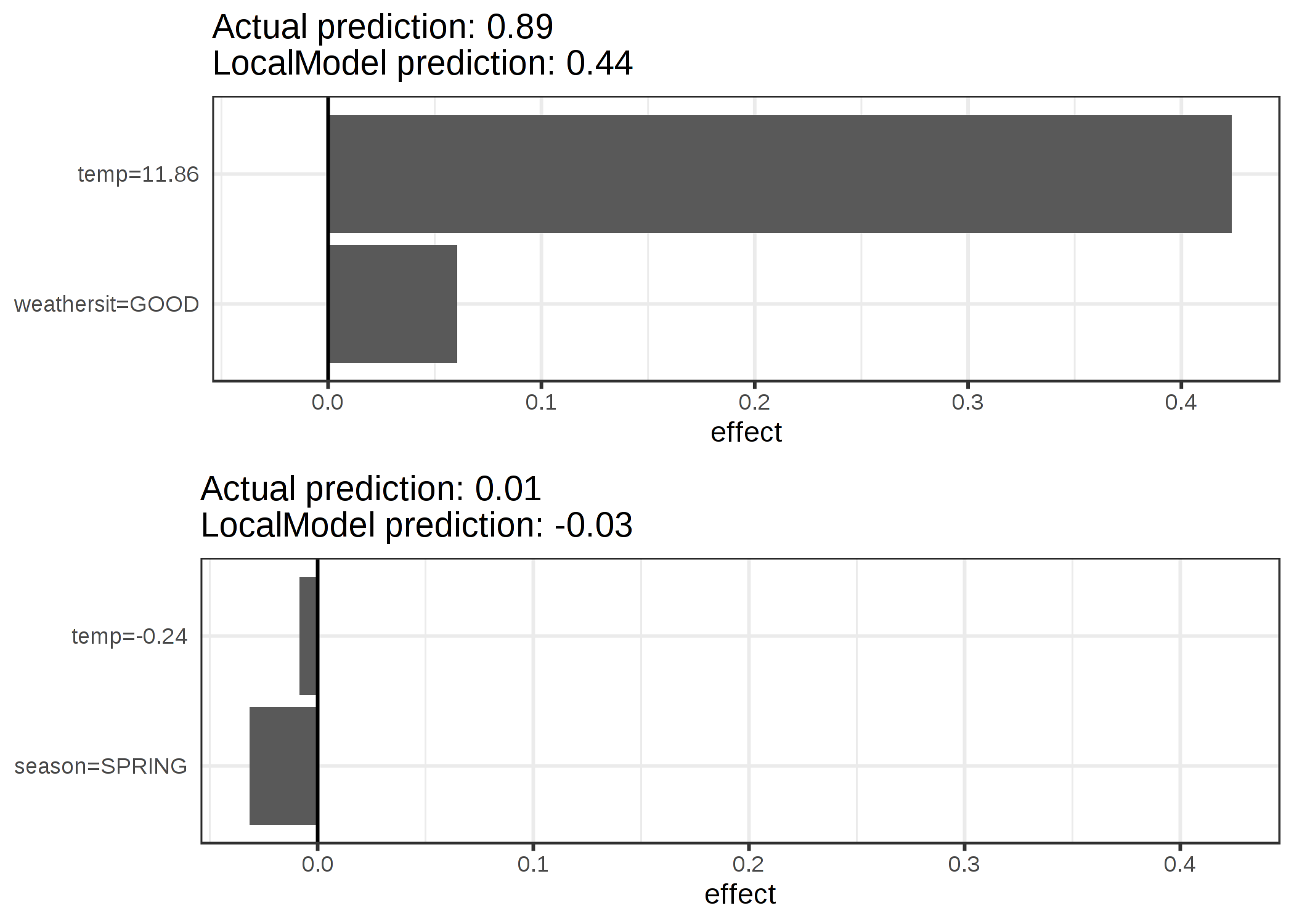
그림 5.35 : 자전거 대여 데이터 세트의 두 인스턴스에 대한 LIME 설명. 더 따뜻한 기온과 좋은 날씨 상황은 예측에 긍정적 인 영향을 미칩니다.
x 축은 기능 효과를 보여줍니다. 가중치에 실제 기능 값을 곱한 것입니다.
그림에서 숫자 특성보다 범주 특성을 해석하는 것이 더 쉽다는 것이 분명해집니다.
한 가지 해결책은 숫자 특성을 빈으로 분류하는 것입니다.
텍스트 용 라임
텍스트의 LIME은 표 형식 데이터의 LIME과 다릅니다. 데이터의 변형은 다르게 생성됩니다.
원본 텍스트에서 시작하여 원본 텍스트에서 단어를 무작위로 제거하여 새 텍스트를 만듭니다.
데이터 세트는 각 단어에 대한 이진 기능으로 표시됩니다.
기능은 해당 단어가 포함 된 경우 1이고 제거 된 경우 0입니다.
5.7.2.1 예
이 예에서는 YouTube 댓글 을 스팸 또는 정상으로 분류 합니다.
블랙 박스 모델은 문서 단어 매트릭스에서 훈련 된 심층적 인 의사 결정 트리입니다.
각 주석은 하나의 문서 (= 한 행)이며 각 열은 주어진 단어의 발생 횟수입니다.
단기 결정 트리는 이해하기 쉽지만이 경우 트리는 매우 깊습니다.
또한이 트리 대신 단어 임베딩 (추상 벡터)에 대해 훈련 된 순환 신경망 또는 지원 벡터 머신이있을 수 있습니다.
이 데이터 세트의 두 주석과 해당 클래스 (스팸의 경우 1, 일반 주석의 경우 0)를 살펴 보겠습니다.
함유/ 량/ 수업
267/ 싸이는 좋은 사람이야/ 0
173/ 크리스마스 노래는 내 채널을 방문하세요! ;)/ 1
에 대한크리스마스노래방문나의채널!;)prob무게다음 단계는 로컬 모델에서 사용되는 데이터 세트의 변형을 만드는 것입니다.
예를 들어, 주석 중 하나의 일부 변형 :
2/ 1/ 0/ 1/ 1/ 0/ 0/ 1/ 0.17/ 0.57
삼/ 0/ 1/ 1/ 1/ 1/ 0/ 1/ 0.17/ 0.71
4/ 1/ 0/ 0/ 1/ 1/ 1/ 1/ 0.99/ 0.71
5/ 1/ 0/ 1/ 1/ 1/ 1/ 1/ 0.99/ 0.86
6/ 0/ 1/ 1/ 1/ 0/ 0/ 1/ 0.17/ 0.57
각 행은 변형입니다.각 열은 문장의 한 단어에 해당합니다.
1은 단어가이 변형의 일부임을 의미하고 0은 단어가 제거되었음을 의미합니다.
변형 중 하나에 해당하는 문장은 " Christmas Song visit my ;)"입니다.
"prob"열은 각 문장 변형에 대해 예상되는 스팸 확률을 보여줍니다.
'가중치'열은 원본 문장에 대한 유사 콘텐츠의 근접성을 보여줍니다.
1에서 제거 된 단어의 비율을 뺀 값으로 계산됩니다.
예를 들어 7 개 단어 중 1 개가 제거 된 경우 근접성은 1-1/7 = 0.86입니다.
다음은 LIME 알고리즘에 의해 발견 된 추정 로컬 가중치와 함께 두 개의 문장 (스팸 하나, 스팸 없음)입니다.
케이스/ label_prob/ 특색/ feature_weight
1/ 0.1701170/ 이다/ 0.000000
1/ 0.1701170/ 좋은/ 0.000000
1/ 0.1701170/ ㅏ/ 0.000000
2/ 0.9939024/ 채널!/ 6.180747
2/ 0.9939024/ 크리스마스/ 0.000000
2/ 0.9939024/ 노래/ 0.000000
이미지 용 라임
"채널"이라는 단어는 스팸의 높은 가능성을 나타냅니다.
스팸이 아닌 댓글의 경우 0이 아닌 가중치가 추정되지 않았습니다.
어떤 단어가 제거 되더라도 예측 된 클래스는 동일하게 유지되기 때문입니다.
이 섹션은 Verena Haunschmid가 작성했습니다.
이미지 용 LIME은 표 형식 데이터 및 텍스트 용 LIME과 다르게 작동합니다.
직관적으로, 하나 이상의 픽셀이 하나의 클래스에 기여하기 때문에 개별 픽셀을 섭동하는 것은별로 의미가 없습니다.
개별 픽셀을 임의로 변경하면 예측이 크게 변경되지 않을 것입니다.
따라서 이미지를 "슈퍼 픽셀"로 분할하고 슈퍼 픽셀을 끄거나 켜면 이미지의 변형이 만들어집니다.
슈퍼 픽셀은 유사한 색상을 가진 상호 연결된 픽셀이며 각 픽셀을 회색과 같은 사용자 정의 색상으로 교체하여 끌 수 있습니다.
사용자는 각 순열에서 슈퍼 픽셀을 끌 확률을 지정할 수도 있습니다.
예
이 예에서는 Inception V3 신경망에 의해 만들어진 분류를 살펴 봅니다.
사용 된 이미지는 그릇에있는 내가 구운 빵을 보여줍니다.
확률에 따라 정렬 된 이미지 당 여러 개의 예측 레이블을 가질 수 있으므로 상위 레이블을 설명 할 수 있습니다.
최상위 예측은 77 %의 확률로 "Bagel"이고 확률이 4 % 인 "Strawberry"가 그 뒤를 따릅니다.
다음 이미지는 "Bagel"과 "Strawberry"에 대한 LIME 설명을 보여줍니다.
설명은 이미지 샘플에 직접 표시 할 수 있습니다.
녹색은 이미지의이 부분이 레이블에 대한 확률을 증가시키고 빨간색은 감소를 의미합니다.

그림 5.36 : 왼쪽 : 빵 한 그릇의 이미지. 중간 및 오른쪽 : Google의 Inception V3 신경망에서 만든 이미지 분류를위한 상위 2 개 클래스 (베이글, 딸기)에 대한 LIME 설명.
"Bagel"에 대한 예측과 설명은 예측이 잘못 되더라도 매우 합리적입니다.
중간에 구멍이 없기 때문에 베이글이 아닙니다.
장점
기본 머신 러닝 모델 을 교체 하더라도 설명을 위해 동일한 로컬 해석 가능한 모델을 사용할 수 있습니다.
설명을 보는 사람들이 의사 결정 트리를 가장 잘 이해한다고 가정합니다.
로컬 대리 모델을 사용하기 때문에 실제로 의사 결정 트리를 사용하여 예측할 필요없이 설명으로 의사 결정 트리를 사용합니다.
예를 들어 SVM을 사용할 수 있습니다.
그리고 xgboost 모델이 더 잘 작동하는 것으로 밝혀지면 SVM을 교체하고 예측을 설명하는 의사 결정 트리로 계속 사용할 수 있습니다.
지역 대리 모델은 해석 가능한 모델을 훈련하고 해석하는 문헌과 경험을 활용합니다.
올가미 또는 짧은 나무를 사용할 때 결과 설명은 짧고 (= 선택적) 대조적 일 수 있습니다.
따라서 그들은 인간 친화적 인 설명을 합니다.
이것이 설명을받는 사람이 평신도이거나 시간이 거의없는 사람인 응용 프로그램에서 LIME을 더 많이 보는 이유입니다.
완전한 어트 리뷰 션으로는 충분하지 않습니다.
따라서 법적으로 예측을 완전히 설명해야하는 컴플라이언스 시나리오에서는 LIME이 보이지 않습니다.
또한 기계 학습 모델을 디버깅 할 때 몇 가지 이유가 아닌 모든 이유를 갖는 것이 유용합니다.
LIME은 표 형식 데이터, 텍스트 및 이미지에 대해 작동 하는 몇 안되는 방법 중 하나입니다 .
충실도 측정 합니다 (해석 모델은 블랙 박스 예측에 근접 얼마나 잘) 우리에게 해석 모델은 관심의 데이터 인스턴스의 동네에 블랙 박스 예측을 설명하는데 얼마나 신뢰할 수있는 좋은 아이디어를 제공합니다.
LIME는 Python ( 라임 라이브러리)과 R ( 라임 패키지 및 iml 패키지 )로 구현되며 사용이 매우 쉽습니다 .
로컬 대리 모델로 작성된 설명 은 원래 모델이 학습 된 것 이외의 다른 (해석 가능한) 기능을 사용할 수 있습니다..
물론 이러한 해석 가능한 기능은 데이터 인스턴스에서 파생되어야합니다.
텍스트 분류기는 추상적 인 단어 임베딩을 특징으로 사용할 수 있지만 설명은 문장에서 단어의 유무를 기반으로 할 수 있습니다.
회귀 모델은 일부 속성의 해석 불가능한 변환에 의존 할 수 있지만 설명은 원래 속성으로 만들 수 있습니다.
예를 들어 회귀 모델은 설문에 대한 답변의 주성분 분석 (PCA)의 구성 요소에 대해 학습 될 수 있지만 LIME는 원래 설문 조사 질문에 대해 학습 될 수 있습니다.
LIME에 대해 해석 가능한 기능을 사용하는 것은 특히 해석 불가능한 기능으로 모델을 학습 한 경우 다른 방법에 비해 큰 이점이 될 수 있습니다.
단점
이웃의 올바른 정의는 테이블 형식 데이터와 함께 LIME을 사용할 때 매우 크고 해결되지 않은 문제입니다.
제 생각에는 이것이 LIME의 가장 큰 문제점이며 LIME 만 사용하길 권하는 이유이기도합니다.
각 응용 프로그램에 대해 다른 커널 설정을 시도하고 설명이 의미가 있는지 직접 확인해야합니다.
불행히도 이것은 좋은 커널 너비를 찾기 위해 제가 줄 수있는 최고의 조언입니다.
현재 LIME 구현에서 샘플링을 개선 할 수 있습니다.
데이터 포인트는 특징 간의 상관 관계를 무시하고 가우스 분포에서 샘플링됩니다.
이것은 지역 설명 모델을 학습하는 데 사용할 수있는 예상치 못한 데이터 포인트로 이어질 수 있습니다.
설명 모델의 복잡성은 미리 정의되어야합니다.
결국 사용자는 항상 충실도와 희소성 사이의 절충안을 정의해야하기 때문에 이것은 작은 불만 일뿐입니다.
또 다른 큰 문제는 설명의 불안정성입니다.
기사 에서 저자는 시뮬레이션 환경에서 매우 가까운 두 지점에 대한 설명이 매우 다양하다는 것을 보여주었습니다.
또한 내 경험상 샘플링 과정을 반복하면 나오는 외식이 다를 수 있습니다.
불안정성은 설명을 신뢰하기 어렵다는 것을 의미하며 매우 비판적이어야합니다.
LIME의 설명은 숨기기 편견에 데이터 과학자에 의해 조작 될 수있다 .
조작 가능성은 LIME으로 생성 된 설명을 신뢰하기 어렵게 만듭니다.
결론 : LIME을 구체적인 구현으로 사용한 로컬 대리 모델은 매우 유망합니다.
그러나이 방법은 아직 개발 단계에 있으며 안전하게 적용하려면 많은 문제를 해결해야합니다.
- Ribeiro, Marco Tulio, Sameer Singh 및 Carlos Guestrin. "왜 내가 당신을 믿어야합니까? : 분류기의 예측을 설명합니다." 지식 발견 및 데이터 마이닝에 관한 22 차 ACM SIGKDD 국제 컨퍼런스의 진행. ACM (2016).
- Alvarez-Melis, David 및 Tommi S. Jaakkola. "해석 성 방법의 견고성." arXiv 사전 인쇄 arXiv : 1806.08049 (2018).
- Slack, Dylan, et al. "Fooling lime and shap : post hoc description methods에 대한 적대적 공격." AI, 윤리 및 사회에 관한 AAAI / ACM 회의의 진행. 2020.
#PDP #이웃의 올바른 정의 #테이블 형식 #데이터와 함께 #LIME을 사용할 때 #매우 크고 해결되지 않은 문제 #LIME의 가장 큰 문제점 #LIME 만 사용하길 권하는 이유 #응용 프로그램 #커널 설정을 시도 #설명이 의미가 있는지 직접 확인 #커널 너비를 찾기 #최고의 조언 #LIME 구현에서 샘플링을 개선 #데이터 포인트 #특징 간의 상관 관계 #가우스 분포에서 샘플링 #완전한 어트 리뷰 션 #법적으로 예측을 완전히 설명해야 #컴플라이언스 #시나리오 #기계 학습 모델 #디버깅 #표 형식 데이터 #텍스트 #이미지에 대해 작동 하는 몇 안되는 방법 중 하나 #충실도 측정 #해석 모델 #블랙 박스 예측에 근접 #우리에게 해석 모델 #관심의 데이터 #인스턴스 #동네에 블랙 박스 #예측을 설명 #얼마나 신뢰할 수있는 좋은 아이디어를 제공 #Python #라임 라이브러리 #R #임 패키지 #iml 패키지 로 구현
***~^0^~ 다른 youtu.be 영상보기,
아래 클릭 하시면 시청 하실수가 있읍니다,
https://www.youtube.com/channel/UCNCZRbUDsmBBKCau3SveIKg

youtu.be/IOzjiVnjFTQ
youtu.be/zc7-qFYKACM
영상을 재미있고 의미있게 보셨다면 ''구독 '좋아요',
그리고 '알림 설정'을 꼭 누르셔서 다음 영상도 함께 해주세요.
^^ 영상 구독 좋아요 누르시면 그 이익금 일부는 불우 이웃에 쓰여집니다ㅡ
많은 성원과 격려 부탁 드립니다,
구독 좋아요 알림설정은 무료입니다,
항상 응원해 주셔서 ~ ♡감사합니다.. -^0^-,,,.
댓글 없음:
댓글 쓰기